Introduction
Recent years have seen a surge of interest in algorithmic collusion in the global antitrust community. Since the publication of Ariel Ezrachi and Maurice Stucke’s influential Virtual Competition in 2016,[1] which brought algorithmic collusion to the forefront of the world of antitrust, numerous articles, commentaries, and agency reports have been published on this topic. In late 2018, the US Federal Trade Commission (FTC) devoted an entire hearing to the implications of artificial intelligence (AI) and algorithms at its Hearings on Competition and Consumer Protection in the 21st Century. António Gomes, Head of the Competition Division at the Organization for Economic Co-operation and Development (OECD), succinctly summarized the concerns about algorithmic collusion in a 2017 interview, stating that developing artificial intelligence (AI) and machine learning that enable algorithms more efficiently to achieve a collusive outcome is “the most complex and subtle way for companies to collude, without explicitly programming algorithms to do so.”[2]
The possibility of tacit collusion is not hard to see in some highly stylized cases. For example, suppose you and I are the only two online sellers of a homogeneous product and we know that our procurement costs are similar. Because our prices are posted online, we also know each other’s pricing.
Suppose I adopt the following strategy: First, I raise and then keep my price high until you also change your price. If you do not raise your price in response to my price increase, I then drop my price to the cost of the product, or even below the cost. The low price “hurts” both your revenue and mine. I keep this “low price” regime for a period of time and then repeat the process of raising and then lowering prices if you do not raise your prices as well. After several rounds of interaction, it is possible that you realize that I appear to be sending you a signal: raise price with me or suffer financial losses. At that point, you might decide to reciprocate my price increase, given our shared interest in long-term profitability. Notice that during the entire interaction, there are no traditional communications between us. We do not even need to know each other as long as all the conditions are met and the intended learning is somehow achieved.[3] Note the “reward-punishment” element in my algorithm, a point which I will return to.
Many have argued that the threat of algorithmic collusion is real and poses much greater challenges for antitrust enforcement than human coordination and collusion. Maurice E. Stucke and Ariel Ezrachi postulate that AI “can expand tacit collusion beyond price, beyond oligopolistic markets, and beyond easy detection.”[4] Michal S. Gal stated that “a more complicated scenario involves tacit collusion among algorithms, reached without the need for a preliminary agreement among them.”[5] Dylan I. Ballard and Amar S. Naik echoed, “Joint conduct by robots is likely to be different—harder to detect, more effective, more stable and persistent.” [6] The background note by the OECD Secretariat also states that “once it has been asserted that market conditions are prone to collusion, it is likely that algorithms learning faster than humans are also able through high-speed trial-and-error to eventually reach a cooperative equilibrium.”[7] These concerns naturally make one wonder what we should do about the possibility of algorithms reaching a collusive outcome even without companies intending that result. Under this premise, many authors then went on to examine the legal challenges and potential solutions.[8]
At the same time, some have emphasized that autonomous algorithmic collusion in real markets is at most a theoretical possibility at the moment given the lack of empirical evidence. For example, Nicolas Petit argued that “AAI [Antitrust and Artificial Intelligence] literature is the closest ever our field came to science-fiction.”[9] Salil K. Mehra stated that, regarding algorithms, the “possibility of enhanced tacit collusion . . . remains theoretical.”[10] Gautier et al. went as far as to argue that “the hype surrounding the capability of algorithms and the potential harm that they can cause to societal welfare is currently unjustified.”[11]
Turning to the views of antitrust enforcers, one senior U.S. Department of Justice (DOJ) Antitrust Division official stated in 2018 that “[C]oncerns about price fixing through algorithms stem from a lack of understanding of the technology, and that tacit collusion through such mechanisms is not illegal without an agreement among participants.” [12] The Competition Bureau of Canada, while recognizing the constantly evolving technology and business practices, pointed out the lack of evidence of such autonomous algorithmic collusion.[13] Even if algorithmic collusion is possible, the French and German antitrust authorities concluded in their recent Joint Report that “the actual impact of the use of algorithms on the stability of collusion in markets is a priori uncertain and depends on the respective market characteristics.”[14]
In the context of this ongoing debate, the evaluation of the plausibility of tacit algorithmic collusion becomes an important exercise. Insights about how algorithms may or may not come to collude are invaluable in focusing attention on the key legal and economic questions, policy dilemmas, and practical real-world evidence. As we will see, the state-of-the-art research has a lot of insights to offer and a good understanding of this literature is a crucial first step to better understanding the antitrust risks of algorithmic pricing and devising better antitrust policies to mitigate those risks. This is the focus of the second part of this chapter in which I survey and draw lessons from the literature on AI and the economics of algorithmic collusion.[15] Most notably, there is growing experimental evidence in both the AI and the economics literature showing that algorithms can be developed to cooperate and even elicit cooperation from competitors. At the same time, as most of these studies acknowledge, there are many technical challenges. As I elaborate below, these challenges imply that one should be able to uncover attempts to develop collusive algorithms ex post, even without technical expertise on the part of the investigators. Of course, existence of technical challenges does not mean that we should simply dismiss the risk of algorithmic collusion. I explain why we should remain vigilant in light of recent studies and research agenda proposed in the AI field. In terms of antitrust policy implications, I argue that at a minimum, designing and deploying autonomous collusive algorithms should be prohibited even if humans take their hands off the wheel after deploying such algorithms and it is an algorithm that ultimately colludes with others.
A more challenging situation is one where an algorithm that is not designed to collude, but rather simply through profit-maximizing learns to collude with competitors. I discuss some recent experimental evidence showing this type of learning to collude is indeed possible. The good news is that these early studies also demonstrate that it is possible to check for collusive conduct, suggesting that we may have the tool to uncover such learned collusion and the black-box nature of an algorithm itself does not necessarily leaves us completely in the dark.
Next, I explore the emerging area of algorithmic compliance. Most of the policy debate on algorithmic collusion so far has focused on the question of how algorithms may harm competition. I argue in this chapter that AI also holds a great deal of promise in enhancing antitrust compliance and helping us combat collusion, human or algorithmic. Specifically, I discuss some existing proposals, draw additional lessons from the recent AI literature, and present potential technical frameworks, inspired by the current machine learning literature, for compliant algorithmic design.
This chapter is not the first to survey and draw lessons from the relevant literature. Earlier discussions can be found in Schwalbe (2018), Deng (2018), Van Uytsel (2018), and more recently Gautier et al (2020), among others.[16] In addition to covering more recent academic research in AI and economics, much of which appeared after 2019, this chapter also offers a broader coverage by bringing two closely related topics together: algorithmic collusion and algorithmic compliance.
While I mainly focus on the evidence and the lessons from academic literature and do not discuss legal approaches such as per se illegality and evidentiary standards, interested readers can find much insightful discussion in Harrington (2019), Gal (2019), and Ezrachi and Stucke (2020), among others.[17] Another important topic that falls outside the scope of this chapter is the important interaction between algorithmic price discrimination and algorithmic collusion, especially the observation that algorithmic price discrimination could hinder collusion. On this topic, interested readers are referred to the 2018 CMA report on pricing algorithms.[18] Finally, the same CMA report and the “2019 Joint Report on Algorithms and Competition” by the Bundeskartellamt and Autorité de la concurrence also review the relevant literature and lay out the latest thinking of these antitrust agencies.
I. A Brief Introduction to AI and Machine Learning[19]
The antitrust community is largely playing catch-up on the technical aspects of AI and machine learning (ML). As the former Acting Chair of the Federal Trade Commission Maureen K. Ohlhausen put it, “[t]he inner workings of these tools are poorly understood by virtually everyone outside the narrow circle of technical experts that directly work in the field.”[20]
While antitrust practitioners, scholars, and policy makers do not need to know all the nuts and bolts of these technologies, a basic understanding is necessary to assess the implications of the AI/ML research on antitrust issues, especially algorithmic collusion. Through a series of examples, I introduce fundamental concepts in ML. Along the way, I also discuss a wide variety of ML applications in the law and economics fields to build the readers’ understanding of AI/ML. Since the discussion here is aimed at readers without a technical background, I prioritize intuitions and pedagogy over analytical or theoretical rigor.
A. Machine Learning vs. Artificial Intelligence
The distinction between ML and AI is not always made in the antitrust literature. This is largely harmless because the discussion about the antitrust concerns is rarely about the definitions or other technical subtleties. It is still helpful that we understand that ML and AI are different concepts. At a basic level, the difference can be understood as the difference between learning and intelligence. Obviously, learning is not intelligence but rather a way to achieve intelligence. Computer scientist Tom Mitchell gave a widely quoted and more formal definition of a machine learning algorithm: “a computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.”[21] To put it simply, machine learning algorithms are computer programs that learn from and improve with experiences. The definition of artificial intelligence, on the other hand, focuses on the question of what intelligence is. In the book Artificial Intelligence: A Modern Approach, the authors listed eight definitions of AI in four categories along two dimensions: (1) thinking and acting humanly, and (2) thinking and acting rationally.[22] Although there are other approaches to obtaining AI, machine learning has become the dominant one in recent years.[23]
B. How Do Machines Learn?
1. Supervised Learning: Learning Through Examples
Econometrics and statistics are now routinely used in antitrust litigation and merger review. As a result, many antitrust practitioners have a basic understanding of techniques. Linear regression, one of the most common analytical tools used in antitrust, turns out to be a machine learning algorithm. While economists and even statisticians seldom use the term “machine learning,” computer scientists do. This is rapidly changing as ML is quickly gaining popularity outside of computer science.
The concept of a regression is simple and intuitive. We do “mental” regressions all the time. For instance, we all know roughly the average temperature of the summer where we have lived for 10 years. When we compute that average, what we do is, in essence, a regression, albeit a very simple one. The key ingredient for such a calculation is a collection of what we could call examples i.e., data on temperature in the summer. Effectively, these examples guide or supervise how we learn. Perhaps not surprisingly, the related ML techniques (regressions included)—i.e., those that rely on the availability of examples—are called supervised learning methods. And the examples are also known as training data or a training sample in the sense that they allow us to train the learning process. You can also see why it makes sense to call them ML methods. They at least mimic in concept how a human learns about our world.[24]
Example: To antitrust attorneys and economists, the most familiar application of regression is probably a model of prices of the product in question. The model relates the prices to the observed drivers of prices (supply and demand factors). The quantity of interest is not limited to prices, however. In a merger analysis, for example, economists may also build regression models for market shares. In fact, regression analysis is rather common in today’s antitrust cases. Not surprisingly, there are many references on regressions written for the antitrust audience.[25]
Example: As more and more electronic documents are preserved and become available, identifying relevant documents in the legal discovery process has become a costly endeavor. Against this backdrop, a set of supervised learning techniques, generally called predictive coding, has been employed to facilitate this process. A prototypical predictive coding approach works as follows. First, a subset of potentially relevant documents is selected. Then human experts review a random subsample of these selected documents and mark the relevant and responsive documents (together with associated metadata such as the author and date). These marked documents provide the examples necessary for the application of supervised learning methods.[26] Since the goal is to label a document as either relevant or not, the problem that predictive coding tries to solve is also known as classification.
Example: Artificial neural network (ANN) has become a buzzword in the recent AI/ML literature, as well as in the antitrust debate, as has the closely related concept of deep learning or deep neural network. ANN has seen a wide variety of successful applications ranging from image recognition to machine translation. But as with any technical jargon, these terms are extremely vague to anyone outside the technical field. It turns out that the basic ANN is just a regression (with technical bells and whistles) and hence another supervised learning method. Figure 1 shows two possible relationships between two quantities. On the graph on the left, the two quantities appear to have a linear relationship in that they appear to move along a straight line, although not perfectly. The graph on the right shows a nonlinear relationship. This is why a regression model that reflects a linear relationship is called a linear regression and a regression model that reflects a nonlinear relationship is called a nonlinear regression.[27] ANN is a type of nonlinear regression, flexible in that it can capture different and complex shapes of nonlinearity. However, this flexibility comes with a cost. Typically, for ANNs to work well, a large number of examples is required. It has been argued that, if ANNs are used to design business decision algorithms, the complexity of this technology could significantly complicate antitrust enforcement efforts.[28] As I have argued elsewhere, whether complex techniques such as ANN are necessarily superior in designing potentially collusive algorithms is unclear.[29]
Figure 1: Illustration of a linear and nonlinear relationship
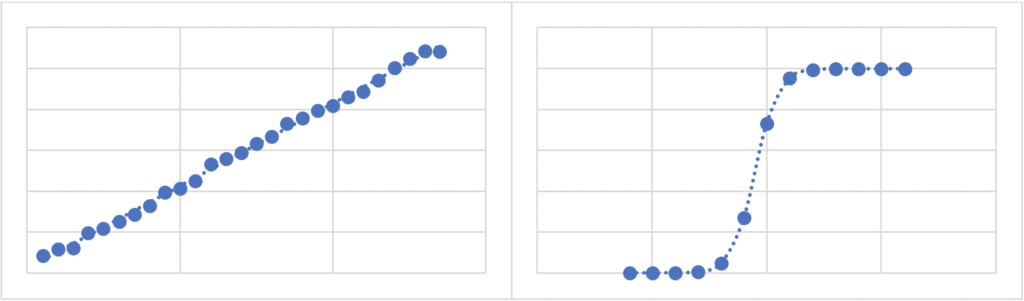
Example: Algorithmic price discrimination has also been a focus of recent discussion in the antitrust literature. The idea is that as companies collect more and more personal data on their customers, they may be increasingly capable of price discrimination among them. In economic terms, companies may be able to use personal data to gauge individual willingness to pay. The availability of such data, as well as customers’ past purchasing/spending behavior (again, examples), could be used to train supervised learning methods to better predict consumer behavior and hence enable companies to offer personalized product options and pricing.[30]
2. Unsupervised Learning: Learning Through Differences
We as humans engage in other cognitive tasks. Consider the following example. Suppose there is a mix of triangles and squares. The task is to put different shapes into separate groups. While this task is incredibly trivial for us, let’s think about exactly how our brains work in such a situation. One plausible hypothesis is that we have “a mental ruler” that measures pairwise differences of—or, using a slightly more technical term, distances between—the shapes. We then put the objects in one group when their differences are “small” and in a different group when the differences are “large.” Figure 2 illustrates this. Note that the task does not require us to know what a triangle or a square look like. In other words, we do not need a set of shapes with labels (triangle vs. square) in order to separate them. The absence of such labelled training data is the hallmark of what is known as unsupervised learning. And the grouping exercise is known as clustering in ML jargon. In these types of learning, the concept of distance is a critical ingredient and underlies even the most sophisticated unsupervised learning techniques.
Figure 2: Classification as unsupervised learning
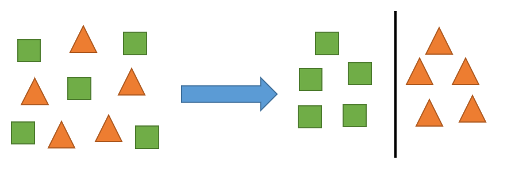
Example: In document review, another objective is to group documents based on certain criteria even before we know whether a document is relevant. For example, one may want to group documents by author or date, or, in more complex cases, by content through the use of other unsupervised ML algorithms.
Example: Novelty or anomaly detection, which identifies the few instances that are different from the majority, is conceptually similar to clustering. In many industries (credit card, telecommunications, etc.), anomaly detection is hugely important in detecting fraud. One simple but powerful idea behind anomaly detection is to start with characterizing the “norm.” For example, once we use a credit card long enough, the card company is able to build a personal profile for our spending behavior. If we have never made a purchase in a foreign country when a transaction just took place in that location, that transaction may be flagged as an anomaly and the card company could issue an alert. In the antitrust domain, similar techniques can be used to detect and monitor cartel formation. I elaborated on how ML/AI could be leveraged to do so in another article.[31] As an example, Joseph Harrington has argued that a sharp increase in the price-cost margin could signal the onset of a cartel.[32] Such a price-cost margin “screen,” as it is commonly known in the cartel detection literature, fits nicely in the unsupervised learning framework. Thus, despite the concerns mentioned earlier that ML/AI could facilitate collusion, the very same set of tools might be used to deter and prevent cartel formation. This is a point I will elaborate below in the context of algorithmic compliance.
3. Reinforcement Learning: Learning Through “Trial and Error”
Another type of machine learning that is particularly relevant to the discussion of algorithmic collusion is known as reinforcement learning (RL). Consider the case of a child learning about different animals. When a child picks up a toy elephant but calls it a giraffe, we would correct her. When she gets it right, we congratulate and reward her. And we repeat that process until she gets it. This process is probably the most common way of reinforcing proper behavior.
Andrew G. Barto and Thomas G. Dietterich give another example. Imagine that you are talking on the phone where the signal is not very good, but moving around to find the right spot.[33] Every time you move, you ask your partner whether he or she can hear you better. You do this until you either find a good spot or give up. Reinforcement learning mimics this type of “trial and error” process. Notice here that the information we receive does not directly tell us where we should go to obtain good reception. In other words, we do not have a collection of examples of location or reception as in a supervised learning case, at least not in a new environment. We make a move and then assess our current situation. As Barto and Dietterich put it, “[w]e have to move around—explore—in order to decide where we should go.” This is a main difference between RL and supervised learning.
Some of the most prominent success stories of RL come from the field of game play. AlphaGo, an RL algorithm, beat world champions at the ancient game of Go in 2016 and 2017. AlphaGo was, however, recently defeated by the next generation of the algorithm AlphaGoZero, losing all 100 games played.[34] In fact, AlphaGoZero uses RL to start from scratch (hence the zero in the name of the algorithm) and trains itself by playing against itself. In the emerging antitrust and AI literature, Ittoo and Petit (2017) argue that “RL is a suitable framework to study the interaction of profit maximizing algorithmic agents because it shares several similarities with the situation of oligopolists in markets.”[35] Many economic studies on algorithmic collusion, that I will discuss below, use RL.
Particularly relevant to algorithmic collusion is the multi-agent learning problem. This is where multiple parties are involved in the learning process and their behavior directly affects each other. For example, in a zero-sum game, if one player wins, another player must lose. In a coordination game such as basketball, the incentives of the players on the same team are generally aligned. In contrast, in a positive-sum game such as prisoner’s dilemma, a stylized model I will discuss in detail below, even though the parties understand that they could achieve a higher overall and individual payoff if they coordinate their behavior, there is a temptation to defect. The last situation resembles the problem cartel members may face and is the most familiar to antitrust attorneys and economists. Research on multi-agent learning in the prisoner’s dilemma type of situation is particularly pertinent to our understanding of algorithmic collusion. We will return to this topic in the next section.
4. Explainable AI
In the recent years, there has been a rapidly growing interest in explainable AI in both academia and the private sector. As the name suggests, explainable AI aims to make algorithmic decision-making understandable to humans.[36] Notably, the Defense Advanced Research Projects Agency (DARPA) sponsors a program called XAI (Explainable Artificial Intelligence).[37] The organization FATML (Fairness, Accountability, and Transparency in Machine Learning) also aims to promote the explainable AI effort. Recent privacy regulations such as GDPR have also put a spotlight on explainability. While we still have a long way to go in the explainable AI research, the industry and academic interest is a promising starting point.[38]
Some of the commercial interest in explainable AI comes from the commercial lending industry because of the regulation and the need to explain lending decisions to consumers, especially when the decision is made by machine learning models. It should be no surprise that the same need for explainability goes well beyond the lending industry. For example, being able to explain algorithmic decisions or recommendations is equally important in the medical and health care domains. Leveraging explainable AI can and should also be an important part of the research program for antitrust compliance by design, a concept I will elaborate below.
The AI research community has proposed several ideas to help achieve interpretability and explainability of AI. Two common approaches, rooted in the technical aspects of AI, are (1) the use of inherently interpretable algorithms (known as “white-box algorithms”) and (2) the use of clever backward engineering (also known as post hoc methods).[39] Naturally, there is not a single definition of explainability, and different domains may find different definitions acceptable. I will argue below that, in the context of algorithmic compliance, an algorithm’s ability to explain and answer why, why not, and what-if questions is particularly helpful.
II. What Do We Know About Algorithmic Collusion?[40]
A. Cartels’ Incentive Problem
To better understand the problems a cartel must solve to sustain an agreement to restrict competition (e.g., raise prices or reduce output), it is instructive to look at the well-known prisoner’s dilemma (PD). Imagine two accomplices of a crime are being interrogated in separate rooms and they cannot communicate. They must decide whether to confess to the crime and hence expose the accomplice. Table 1 shows the consequences of their decisions.
Table 1: A Prisoner’s Dilemma: Understanding the incentive problem of a cartel
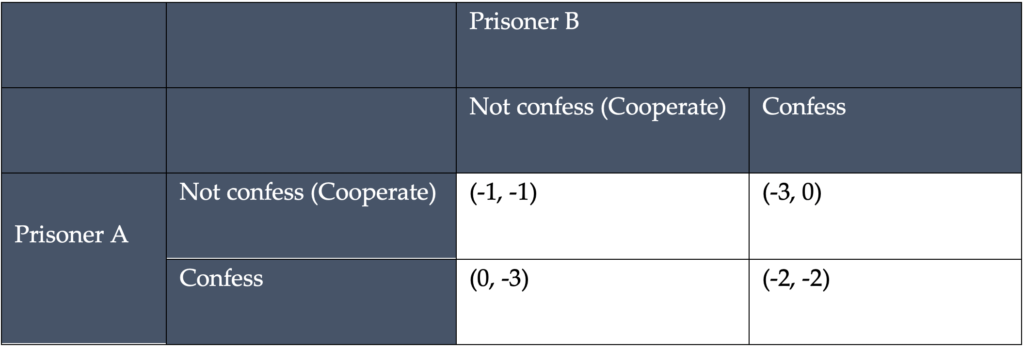
The two rows and two columns in Table 1 represent the two prisoners and their two possible choices. For example, the cell (-1, -1) tells us that if neither confesses, each would get one year in prison. Similarly, if Prisoner A does not confess but Prisoner B does, then Prisoner A gets three years in jail and Prisoner B goes free; this corresponds to the upper right cell (-3, 0). Since the situation is symmetric, the lower left cell is (0, -3) and the penalty is reversed. Finally, if both confess, then each would get two years (as shown in the lower right cell).
Given these numbers, it is clear from a joint-interest perspective that the best outcome is (-1, -1), a total of two years. And the prisoners can achieve that by “cooperating” (i.e., not confessing). Unfortunately for the prisoners, since confessing is the rational move regardless of what the other does, both will end up confessing, leading to two years for each, an outcome strictly worse than the “cooperative” outcome. It is not surprising that cartel members face a similar type of incentive problem. They are both better off if they cooperate (e.g., raise prices or reduce output). But at the same time, if I know that my competitors are raising prices, I have an incentive to lower mine to steal the business and increase my revenue. Since a formal cartel contract is not enforceable in most if not all jurisdictions, they have to find other and often imperfect ways to implement their agreement.
A critical point is that solving this incentive problem is key to the success of a cartel: the use of an algorithm does not magically remove this fundamental incentive problem that a cartel faces. And unlike the “one-shot” situation in the standard prisoner’s dilemma, competitors interact with each other repeatedly in the market. It turns out that in repeated interactions, there is “more hope” that firms can learn to cooperate. In fact, repeated interaction is an important reason that tacit collusion emerges in the stylized example discussed earlier in the chapter.
B. The AI Literature
Is there any evidence that computer algorithms can (tacitly) collude? We have not seen tacitly colluding robots in real markets. The infamous Topkins and Trod cases involve the use of pricing algorithms that implement human agreements.[41] However, they are not the focus of this chapter.
But there is growing theoretical and experimental evidence showing that certain algorithms could lead to tacit coordination. In the AI field of multi-agent learning, there is an active literature on designing algorithms that can cooperate and even elicit cooperation in social dilemmas such as the PD. The AI researchers’ goal is, of course, not to design evil collusive robots. Rather, they are interested in designing AIs that have the ability to cooperate with each other and with humans for social good.[42]
One algorithm that has been found to be conducive to cooperative behavior in experimental settings is the so-called tit-for-tat (TFT) algorithm.[43] This strategy starts with cooperation, but then each party will simply copy exactly what the opponent did in the previous period in repeated interaction. Intuitively, if two opponents start by cooperating, then the very definition of the TFT algorithm dictates their continued cooperation. But will competitors have an incentive to deviate from cooperation? The answer is that they might not, if they realize that despite the higher profit they could obtain by cheating in the current period, they will have to compete with others and hence generate lower profit in the future. While not guaranteed, if the firms care enough about future profitability, they might not find it worthwhile to deviate.
The TFT algorithm, despite its simplicity, intuitive appeal, and some experimental success, has a number of limitations. For example, to implement TFT, one needs to know what the competitors have done (because TFT copies the competitors’ behavior) and the consequences of future interactions (because they need to assess if it pays to cooperate). In the real world, firms typically do not possess that information, except in certain special cases.[44]
In recent years, there has been more research that aims to relax various assumptions and construct more robust cooperative algorithms. In a study published in 2018, a team of researchers designed an expert system (a type of AI technology) that can cooperate with opposing players in a variety of situations. Intuitively speaking, an expert system requires two components: a pool of “experts” or strategies and a mechanism to choose a particular subset of strategies given the information available to the AI system. Among the pool of experts in their algorithm are TFT-style “trigger” strategies. The researchers found that although the previous version of their expert system (codenamed S++) was better than many other algorithms at cooperating, the performance of a modified algorithm (codenamed S#) is significantly better, especially when playing against humans, because it is equipped with the capability to communicate (through costless “cheap” talk based on a set of pre-programmed messages).[45] But the engineering process is by no means easy or obvious. In addition to the capability to communicate, the researchers also attribute the success of their algorithm to a carefully selected pool of experts and an optimization procedure that is “non-conventional.”[46] We will discuss the implications of this study, especially the algorithm’s ability to communicate and the associated technical challenges, on antitrust and compliance below.
Even more recently, two researchers developed algorithms that can cooperate with opponents in similar social dilemmas.[47] One of their algorithms was, in fact, inspired by the TFT algorithm. Specifically, the researchers tried to relax the strong information requirements of the naïve TFT algorithm. Another recent study adopted an interesting approach to design an algorithm that promotes cooperation. Its idea is to introduce an additional planning agent that can distribute rewards or punishments to the algorithmic players as a way to guide them to cooperation, analogous to an algorithmic hub and spoke scheme.[48] Another group of researchers recently proposed an algorithm that explicitly takes into account the opponent’s learning through interactions and found that their algorithm worked well in eliciting cooperative behavior.[49] Yet other researchers tried to make algorithms learn to cooperate with others by modifying the algorithm’s objective. For a pricing algorithm, the most natural objective would be to maximize profits. But one study shows that by adopting an objective that “encourages an [AI] agent to imagine the consequences of sticking to the status-quo,” their algorithm is able to learn to cooperate “without sharing rewards, gradients, or using a communication channel.”[50] The researchers credit this capability to the fact that the “imagined stickiness ensures that an agent gets a better estimate of the cooperative or selfish policy.”[51] Finally, a carefully designed reinforcement learning algorithm, called “Foolproof Cooperative Learning” (FCL), was recently developed and shown to learn to play TFT, without being explicitly programmed to do so.[52] In the researchers’ words, FCL, “by construction, converges to a Tit-for-Tat behavior, cooperative against itself and retaliatory against selfish algorithms” and “FCL is an example of learning equilibrium that forces a cooperative behavior.”[53] New AI research on the topic of machine-machine and machine-human cooperation continues to appear.
With growing experimental evidence that algorithms can be designed to tacitly cooperate, the next question naturally becomes whether a collusive pricing algorithm inspired by this research is available for use in the real world. The answer is that despite the promising theoretical and experimental results discussed above, we have a long way to go.
Several limitations are worth keeping in mind. First, almost all of these studies focus on two players (a duopoly). It is well recognized that everything else being equal, as the number of players increases, collusion, tacit or explicit, becomes more difficult. Second, the type of games (e.g., repeated prisoner’s dilemma and its variants) is simplistic and the universe of possible strategies in these experimental studies are rather limited, especially when compared to the real business world.[54] Third, most of these experimental studies assume a stable market environment. For example, in most AI studies, the payoffs to the AI agents, as well as the environment in which AI agents operate, are typically fixed.[55] This is a significant limitation because demand variability and uncertainty is not just a norm in the real world, but also has been long recognized by economists to have important implications on how cartels operate. For example, with imperfect monitoring, if the market price is falling, cartel firms may have a hard time figuring out whether the falling price is due to cheating or to declining demand (“a negative demand shock”). In fact, the economic literature shows that a rational cartel would need to internalize the disruptive nature of demand uncertainty when the cartel monitoring is imperfect.[56] Interestingly, as we will discuss in the next section, recent economic studies have shown that reduced demand uncertainty, achieved by the use of algorithms, for example, may actually make a cartel more difficult to sustain.
Another important observation from the AI research is that the algorithms being designed are not necessarily what economists call “equilibrium” strategies. Equilibrium strategies are “stable” in the sense that, if you know that you and your competitors adopt this strategy, none of you would have the incentive to switch to another strategy.[57] That is not the case for some of the algorithms recently developed by AI researchers.[58] In a recent study mentioned earlier, despite the promising experimental findings, the researchers acknowledge that unless an algorithm is an equilibrium learning strategy, it can be exploited by others, meaning that players may have an incentive to move away from their proposed algorithm.[59] This observation has a powerful implication: unless firms are fully committed to a “collusive” algorithm that is not an equilibrium strategy, there will be a temptation for the (rational) firms to change their strategy and hence potentially disrupt the status quo or a potentially tacitly collusive outcome.
Also relevant is whether the AI agents are symmetric; in other words, whether the opposing players have identical payoffs if they adopt the same strategies. In fact, almost all the AI studies that use the repeated prisoner’s dilemma or its variants focus on the symmetric case. As I will discuss in the next section, the existence of various types of asymmetry (cost, market share, etc.) tends to make reaching a cartel agreement harder and the use of algorithms is unlikely to change that. Similar to the case of time-varying demand, economists have shown that a rational cartel may also need to explicitly take asymmetry into account and adapt its pricing arrangement accordingly.[60] So there are good reasons to suspect that the AI algorithms designed under symmetry do not necessarily fare well in more realistic, asymmetric situations.
Given all these real-world complications, it is not surprising that empirically, as of now, there is no known case of tacitly colluding robots in the real world. But at the same time, the AI literature offers several insights that inform us how best to approach the antitrust risk of algorithmic collusion. The most significant, and perhaps also the most obvious is that designing algorithms with proven capability to tacitly collude in realistic situations is a challenging technical problem. The large-scale study (Crandall et al, 2018) started with 25 algorithms and found that, in a variety of contexts, not all of them learned to cooperate effectively, either with themselves or with other algorithmic players. In fact, the researchers identified the more successful algorithms only after extensive experiments and careful “non-conventional” design choices. They highlighted a number of technical challenges. For example, they pointed out that a good algorithm must be flexible in that it needs to learn to cooperate with others without necessarily having prior knowledge of their behaviors. But to do that, the algorithm must be able to deter potentially exploitative behavior from others and, “when beneficial, determine how to elicit cooperation from a (potentially distrustful) opponent who might be disinclined to cooperate.”[61] The researchers went on to state that these challenges often cause AI algorithms to defect rather than to cooperate “even when doing so would be beneficial to the algorithm’s long-term payoffs.”[62] Another paper further noted “[l]earning successfully in such circumstances is challenging since the changing strategies of learning associates creates a non-stationary environment that is problematic for traditional artificial learning algorithms.”[63] One of the researchers of this study reiterated in a 2020 article that “despite substantial progress to date, existing agent-modeling methods too often (a) have unrealistic computational requirements and data needs; (b) fail to properly generalize across environments, tasks, and associates; and (c) guide behavior toward inefficient (myopic) solutions.”[64] Indeed, each one of the AI studies reviewed above had to use clever engineering to confront and solve some of these challenges.
In the next section, I will discuss and comment on some important, recent experimental studies in which standard reinforcement learning pricing algorithms are shown to be able to learn to collude with one another without any special design tweaks or instructions from the human developers. Given the limitations to be discussed below and the early stage of the recent research, however, it is safe to conclude that to design an algorithm that has some degree of guaranteed success in eliciting tacit collusion in realistic situations and timeframes, the capability to collude most likely needs to be an explicit design feature.[65]
This means that there may very well be important leads that the antitrust agencies and even private litigants could look for in an investigation or a discovery process.[66] Several types of documents are of particular interest. These include any internal document that sheds light on the design goals of the algorithm, any documented behavior of the algorithm, and any document that suggests that the developers had revised and modified their algorithm to further the goal of tacit coordination. Another type of document that should raise red flags is any marketing and promotional material that suggests that the developers may have promoted the algorithm’s capability to elicit coordination from competitors. Note that it is not necessary for the investigators to have an intimate understanding of the technical aspects of the AI algorithm to look for such evidence.[67]
C. The Economics Literature
The economics literature that explicitly examines algorithmic collusion is more limited than the AI literature surveyed above but growing rapidly.[68] In an experimental study, a team of researchers recently showed that their algorithm successfully induced human rivals to fully collude in a simulated duopoly market with a homogenous product and that such a collusive outcome was reached relatively quickly.[69] Despite the various limitations, many of which are discussed in the previous section, it is one of the strongest pieces of evidence that supports the algorithmic collusion hypothesis in economics. But an important observation relevant to our discussion is that their algorithmic design was based on the so-called zero-determinant strategy (ZDS) that is known to be able to extort and elicit cooperation from opponents in iterated prisoners’ dilemmas.[70] I argue below that this type of algorithmic design approach should raise red flags regardless of the fact that it is the algorithms, not the humans, that ultimately collude with others.
Turning to algorithms that are not explicitly designed to collude or elicit collusion, one early study showed that a particular type of RL algorithm called Q-learning could lead to some degree of imperfect tacit collusion in a quantity-setting environment.[71] More recently, another study reported a similar finding in a price-setting environment.[72] Both are important contributions and demonstrate the theoretical possibility of algorithmic collusion, when collusion is not an explicit design goal.[73] The strongest evidence comes from another even more recent study, in which the researchers found that their RL algorithms “consistently learn to charge supra-competitive prices, without communicating with one another . . . This finding is robust to asymmetries in cost or demand, changes in the number of players, and various forms of uncertainty.” [74]
One of the most interesting observations in this study is that the RL algorithm appears to have learned to punish the “cheater” and reward the “collaborator.”[75] This type of reward-punishment strategy has been labeled as problematic collusive behavior and is the defining characteristic of collusion by Harrington (2019).[76] And it is this observation that led the researchers to conclude that the RL algorithm has learned to tacitly collude.
The finding of the RL algorithm’s robust tendency to tacitly collude is concerning. A common caveat for such an experimental study, however, is that the artificial market is too simplistic relative to any real market. Other challenges and limitations have already been discussed in the previous section.[77] I highlight one difficulty here.[78] The RL algorithm in the researchers’ experiments takes an average of 850,000 periods of training to learn to “tacitly collude.”[79] Although that amounts to less than one minute of CPU time, it means that, in the real world, the algorithm “learns” after over 2,300 years if they change prices daily, or over 1.5 years if they change every minute. And this is after the researchers limited the set of possible prices the algorithm could choose from.[80] It is unlikely that any company would be amenable to allow the algorithm to trial-and-error with actual prices, let alone for years. Future technological advances, especially in markets where firms’ algorithms interact at (ultra-)high frequency, may significantly reduce the learning time, but the point is that a “collusive” algorithm is arguably less relevant to the antitrust community if it takes an unrealistically long time to learn to collude. Indeed, the longer the learning takes, the more likely the market structure will change during the learning stage. For example, the number of competitors may change due to entries and exits; new technologies may emerge and disrupt an industry; even the macroeconomic environment may change, all of which create a “non-stationary” environment, making it difficult for an algorithm to learn. Recognizing this limitation, the researchers focused entirely on the algorithmic behavior after the training process had completed.[81] In the researchers’ words, this means that the learning happens “off the job.”
If the training is done offline in a lab environment, the developers could in principle assess algorithmic behavior in a controlled environment as well. In fact, the researchers’ demonstration that detecting collusive behavior is possible shows that the black-box nature of algorithms does not necessarily inhibit our understanding of algorithmic behavior. We do need to keep in mind, however, that algorithmic behavior manifested in controlled experiments will be driven by the assumptions imposed in that environment and as a result, may or may not materialize in real markets.
Another paper (Klein, 2019) follows a similar line of research and shows that Q-learning can also lead to tacit collusion in a simulated environment of sequential competition.[82] Among other assumptions, the study finds that the algorithmic behavior depends critically on the number of prices the AI algorithm is allowed to choose from. Specifically, the algorithms do not consistently learn to price optimally (i.e., play “best response”) with respect to each other. They do so in 312 out of 1,000 simulation experiments (31.2%) when they have seven prices to choose from and only 10 out of 1,000 experiments (1%) when they have 25 prices to choose from.[83] Furthermore, while the algorithm also exhibits the reward-punishment behavior similar to that documented by the previous study when it learns to price at the fully collusive (i.e., monopoly) level, the researcher was able to document this behavior in only 13.5% of their experiments when there are seven prices to choose from and only 1.9% (with at most one price increment away from the monopoly level) when there are 13 possible prices.[84] To put the finding of algorithmic collusion in perspective, the author noted that “for the environment considered in this paper, humans are expected to show a superior collusive performance because tacit collusion is relatively straightforward.”[85] As the researcher recognizes, “while this [the finding of the paper] shows that autonomous algorithmic collusion is in principle possible, practical limitations remain (in particular long learning and required stationarity).”[86]
Another interesting recent article (Salcedo, 2016) provides a set of sufficient conditions under which the use of pricing algorithms leads to tacit collusion.[87] The author considered an algorithmic version of an “invitation to collude.” Three conditions must be true for algorithmic collusion to materialize in his framework. First, competitors should be able to decode each other’s pricing algorithms. Second, after decoding others’ algorithms, the competitors should be able to revise their own pricing algorithms in response. Third, firms should not be able to revise or change their algorithms too fast.[88] Intuitively, under these conditions, a firm could essentially communicate its intent to collude by adopting a “collusive” algorithm and letting the competitor decode it. Once this invitation to collude is decoded, the competitor can then choose to follow the lead or not. When making the decision, the firm on the receiving end will naturally be concerned about the possibility that the invitation is no more than a trick and that once that firm starts to cooperate, the competitor would take advantage of it by immediately reversing course (say, by immediately lowering prices to steal customers away). This is where the third condition comes into the picture. If the firms understand that changing the strategy takes time, then the receiving firm’s concern would be alleviated. Schwalbe (2018) has argued that the situation postulated by Salcedo is an example of direct communication (through the decoding of an algorithm), rather than tacit and is thus equivalent to explicit collusion.[89]
1. Algorithms and Structural Characteristics
One strand of economic literature that has received much attention in the antitrust community identifies the structural characteristics that tend to facilitate/disrupt collusion. We’ve already discussed some of these when we assessed the limitations of the AI studies. In this section, we provide a more systematic discussion on how algorithms could impact these market characteristics.
A partial list of such structural characteristics that some have argued tend to facilitate collusion includes the following:
- Higher market transparency
- More stable demand
- Small and frequent purchases by customers
- Symmetric competitors
- Fewer competitors
- More homogeneous products
- Higher barriers to entry
Market transparency is one obvious characteristic that an algorithm could potentially enhance. Some have argued that algorithm-enhanced market transparency will in turn facilitate collusion. For example, the Autorité de la Concurrence and Bundeskartellamt stated in their “2016 Joint Report on Competition Law and Data” that “. . . market transparency . . . gains new relevance due to technical developments such as sophisticated computer algorithms. For example, by processing all available information and thus monitoring and analysing or anticipating their competitors’ responses to current and future prices, competitors may easier be able to find a sustainable supra-competitive price equilibrium which they can agree on.”[90] In their recent “2019 Joint Report on Algorithms and Competition”, the agencies again noted that “[m]arket transparency for companies facilitates the detection of deviations and thus can increase the stability of collusion. By allowing a greater gathering and processing of information, monitoring algorithms collecting these data could thus foster collusion.”[91] Francisco Beneke and Mark-Oliver Mackenrodt also stated that “coordinated supra-competitive pricing is in many settings difficult due to uncertainties regarding costs of competitors and other variables. If the algorithms can learn how to make accurate predictions on these points, then the need to solve these problems with face-to-face meetings may disappear. . . . One common source of equilibrium instability in oligopoly settings is said to be changes in demand.”[92]
Recent empirical evidence shows that increased transparency may have indeed led to potential tacit collusion in real markets.[93] While these arguments highlight the ways in which transparency could facilitate collusion, it is critical that we recognize that under some conditions, transparency can also undermine it. In fact, firms in several cartels took pains to limit the information they shared and maintained a certain degree of privacy. For example, in the isostatic graphite cartel, firms would enter their own sales on a calculator that was then passed around the table so that only the aggregate sales were observed. Thus, they could compute their own market shares but not their competitors’. In the plasterboard cartel, firms set up a system for exchanging information through an independent third party that would consolidate and then circulate the aggregate information among the firms.[94]
Sugaya and Wolitzky (2018) provided an economic theory to explain why privacy (i.e., less transparency) can be beneficial to the sustainability of a cartel.[95] Specifically, they considered cartels that engage in market/customer allocation; that is, cartel firms agree to serve only their own “home” market and not to sell to the competitors’ home markets. The basic intuition is as follows: When the demand in your home market is strong (and hence you have an incentive to raise your prices), transparency about the (higher) demand in your home market, your costs, and your prices would give the other cartel firms more incentive to enter your markets simply because there would be more to gain. This incentive is stronger, the less patient the competitors are. Along similar lines, Miklos-Thal and Tucker (2019) build a theoretical model to show that while “better forecasting allows colluding firms to better tailor prices to demand conditions, it also increases each firm’s temptation to deviate to a lower price in time periods of high predicted demand.”[96] This result leads them to conclude that “despite concerns expressed by policy makers, better forecasting and algorithms can lead to lower prices and higher consumer surplus.”[97] Under a different economic model, O’Connor and Wilson (2019) reached the same conclusion that greater transparency and clarity about the demand has ambiguous effects on consumer welfare and firm profits. These authors therefore call for a cautious antitrust policy toward the use of AI algorithms.[98]
Sugaya and Wolitzky (2018) gave an analogy that should make it intuitively clear why more information does not necessarily facilitate collusion. Imagine there are two sellers at a park.[99] They can bring either ice cream or umbrellas to sell. Ice cream is in demand on sunny days and umbrellas are in demand on rainy days, and if both sellers bring the same good, they sell at a reduced price. In the absence of weather forecasts, it is an equilibrium for one seller to bring ice cream, the other to bring umbrellas as each expects to receive half the monopoly profits. But if the two sellers know the weather with a high degree of certainty before they pack their carts, they would both have incentive to bring the in-demand good and end up competing and splitting the reduced profits. Thus, in this simple example, transparency about the weather (though not transparency about the firms’ actions) actually hinders collusion.
Some have also argued that an algorithm’s speed could prevent cartels from cheating because any deviation from a tacitly or explicitly agreed-upon price could be detected and potentially retaliated against immediately.[100] For example, OECD’s “Report on Algorithms and Collusion” states that “the advent of the digital economy has revolutionized the speed at which firms can make business decisions. . . . If automation through pricing algorithms is added to digitalization, prices may be updated in real-time, allowing for an immediate retaliation to deviations from collusion.”[101] Beneke and Mackenrodt echoed: “… price lags will tend to disappear since pricing software can react instantly to changes from competitors. Therefore, short-term gains from price cuts will decrease in markets. . . .”[102] The observation that faster reaction reduces the incentive to deviate in the first place under perfect monitoring has been recognized in the economic literature as well. But economists have also shown that faster responses can be a double-edged sword when it comes to cartel stability under imperfect monitoring. A seminal article in this literature (Sannikov & Skrzypacz, 2007) shows that under some conditions, if market information arrives continuously and firms can react to it quickly (for instance, with flexible production technologies), collusion becomes very difficult.[103] Why is that?
Recall that earlier I discussed a situation where consumer demand is volatile and a cartel, producing a homogeneous product, can only observe the market price but not the production of individual cartel members. In that situation, when the firms observe a lower market price, they cannot perfectly tell whether it is due to someone deviating from their agreement or simply due to weak aggregate demand. Firms can deter cheating by resorting to price wars (by producing more, for example) when the price falls below a certain level. In this framework, when the time firms take to adjust their production becomes shorter, there are two counteracting effects on the sustainability of a cartel. On the one hand, the ability to change their production quickly means that they could start a price war as quickly as they want to. This tends to reduce the incentive to cheat and hence makes a cartel more sustainable. On the other hand, when the demand is noisy and hence the market price moves due to short-term idiosyncratic factors, firms that are constantly watching the market price trying to detect potential cheating will likely receive many idiosyncratic signals of lower prices. Under additional assumptions, the study shows that firms will simply commit too many Type I errors (false positives): that is, start price wars too often to sustain collusion in this environment. An experimental study yields results largely consistent with these theoretical predictions.[104] In fact, some studies have shown that one way a cartel could combat the issue is to deliberately delay the information flow.[105] At a theoretical level, it is not hard to imagine that using algorithms to continuously monitor the market information and enable firms to react quickly could bring the reality closer to the one considered in these research studies.[106]
The effect of algorithms on many other factors is ambiguous.[107] Take asymmetry as an example. In general, economists believe that various forms of asymmetry among competitors tend to make (efficient) collusion more difficult.[108] A leading example is one where competitors have different cost structures (i.e., cost asymmetry). In this case, firms may find it difficult to agree to a common price because a lower-cost firm has an incentive to set a lower price than a higher-cost firm. This tends to make the coordination problem harder. In addition, as a research paper put it, “[E]ven if firms agree on a given collusive price, low-cost firms will be more difficult to discipline, both because they might gain more from undercutting their rivals and because they have less to fear from a possible retaliation from high-cost firms.”[109]
Even if firms use the same algorithm provider, they are likely to customize their versions of the algorithm. As a simple example, imagine that some developers tell us that their algorithm is going to increase our profit. But what profit? Certainly, an algorithm that aims to maximize short-term profit is not going to behave the same way as an algorithm that aims to maximize long-term profit.[110] Similarly, we also expect an algorithm to incorporate firm-specific cost information or objectives in its decision-making process. For example, Feedvisor, a provider of pricing algorithms for third-party Amazon marketplace sellers, states that its “pricing strategies for each individual SKU can be set based on a seller’s business objectives, such as revenue optimization, profit, or liquidation.” [111] That is, even if the algorithms adopted by competitors have the same structure and capability, they do not necessarily or automatically eliminate asymmetry. In fact, the algorithms are typically expected to reflect, if not exacerbate, existing asymmetries. Finally, pricing algorithms, by themselves, are unlikely to affect many other structural characteristics, especially those related to demand and firms’ product offerings.
It is worth emphasizing that these structural factors only predict which markets are more susceptible to coordination, not whether market participants are explicitly or tacitly colluding.
D. Implications for Antitrust Compliance and Policy
Despite the significant technical challenges in designing tacitly collusive algorithms and the ambiguous economic relationship between algorithms and collusion, the AI and economic research I surveyed above clearly shows that algorithmic collusion is possible. If there is one lesson we have learned from past experiences, it is that predicting the future of technology is notoriously difficult. In this section, I discuss the reasons we should stay vigilant and what we can do to combat the risk of algorithmic collusion.
As a starting point, a potentially effective antitrust policy is to explicitly prohibit the development and deployment of autonomously collusive algorithms. Consider the algorithmic design that equips an algorithm with the ability to communicate. In a study discussed earlier, the algorithm’s capability to learn to cooperate and maintain cooperation (Crandall et al, 2018) is significantly improved when it can communicate with others (including human counterparts) through costless, non-binding messages (“cheap talk”). That research demonstrates that, just like humans, the ability to communicate can be a key to forging a cooperative relationship among competing algorithms.[112] Recognizing the importance of such non-binding signals, the lead author of that study argued in a recent article that “research into developing algorithms that better utilize non-binding communication signals should be more abundant” because “non-binding communication signals are not being given sufficient attention in many scenarios and algorithms considered by AI researchers. . . .”[113] The author also believes that “the potential value of better using non-binding communication signals often outweighs” the challenges in doing so.[114] He went on to propose a two-step strategy, the first step of which is for AI algorithms to “learn (or being given) a shared-communication protocol.”[115] As the author noted, several strands of AI research, including on automated negotiation[116] and vocabulary alignment[117] can further improve and even automate algorithmic communication. Future research along these lines could accelerate the development of algorithms capable of reaching and sustaining collusion. Designs that enable pricing algorithms to communicate and even negotiate with competitors (humans or algorithms) with the goal of achieving collusion put consumer welfare at risk even if such capability is encoded in machine-readable syntax and humans do not participate in the actual communication or negotiation.[118]
I also discussed AI studies in which researchers were able to design cooperative algorithms by carefully modifying their objective.[119] Any such design modifications with the goal of ensuring or eliciting cooperative behavior from competitors are another example of problematic conduct, regardless of whether supra-competitive prices are ultimately set “autonomously” by the algorithms. More generally, absent procompetitive justifications, basing the design of pricing algorithms on those already known to elicit and maintain cooperation is highly suspicious. The success of such an approach in experimental studies is another reason why we should remain vigilant.[120]
The current research has more to offer. For example, antitrust scholars have advocated more research to understand “collusive” features of an algorithm. Ezrachi and Stucke called this type of research a “collusion incubator.”[121] Harrington went a step further and proposed a detailed research program and discussed its promises and challenges.[122] Specifically, he proposed to create simulated market settings to test and identify algorithmic properties that support supra-competitive prices. AI researchers, in their pursuit of robots capable of cooperating with others, have laid some important groundwork for this effort. On this point, let’s take a closer look at an instructive algorithmic taxonomy discussed in a recent AI study.[123]
Based on this particular taxonomy, algorithms such as TFT are examples of the type of algorithms known as Leaders. Leader algorithms “begin with the end in mind” and “focus on finding a ‘win-win’ solution” by pursuing an answer to the question of what desirable outcome is likely to be acceptable to the counterpart. And once the outcome (e.g., joint-monopoly price) is selected by Leaders, they would then stick to it, as long as their counterparts cooperate and “otherwise punish deviations from the outcome to try to promote its value.”[124] This is precisely the type of problematic reward and punishment scheme discussed by Harrington (2019). If for one reason or another, the counterpart does not accept the outcome, the more flexible Builders algorithms would move on to iteratively seek for consensus and compromises. An example of this type of Builder algorithm is the expert system proposed by Crandall et al (2019) that I discussed earlier. From an antitrust perspective, this is a helpful taxonomy in that it suggests that Leader and Builder algorithms are probably what we should be most concerned about.
1. A Comment on Digital Markets[125]
Before we move on to the lessons for antitrust compliance more specifically, I want to comment on the implications of pricing algorithms on digital markets. Not surprisingly, as more and more businesses are moving online and have at least some online presence, “digital” market is becoming increasingly encompassing. However, many would probably agree that a quintessential digital market should have the following characteristics:
- Prices are posted online, transparent, and potentially scrapable; and
- Competitors sell largely homogenous products either on the same online store (e.g., Amazon) or on their own online websites (e.g., Staples.com and OfficeDepot.com).
In fact, the simulated markets in which Calvano et al (2020) and Klein (2019) demonstrated the possibility of tacit collusion by self-learning algorithms share these characteristics. So, there are good reasons why this type of markets is of great interest and potentially more susceptible to algorithmic collusion. More generally, to the extent that a market already exhibits structural characteristics that are conducive to coordination, the CMA report argues that “algorithmic pricing may be more likely to facilitate collusion.”[126]
As Schwalbe (2018) pointed out, most of the earlier literature on the risk of algorithmic collusion in this type of digital market, however, is illustrated not by self-learning AI algorithms but by simple deterministic pricing rules, most commonly, price-matching ones. Intuitively, if algorithms enable a seller to continuously monitor competitor prices and automatically match them, there would be less competitive pressure and thus less incentive to lower prices to begin with, especially when the algorithms can detect price changes and react instantaneously. This impact on firms’ incentives is no different from other types of price guarantees, however, and “does not pose any novel problems for competition that would not occur, for example, with the widespread use of price guarantees.”[127]
We have already discussed the relationship between market transparency and tacit collusion and, in particular, when transparency could facilitate or hinder (algorithmic) collusion. Even in situations where transparency unequivocally facilitates collusion, it is not implausible that oligopolistic firms sophisticated enough to use complex pricing algorithms, upon seeing a profitable deviation, would use technologies or other workarounds to obscure transparency and secure higher profits. The simple practice of allowing a customer to see the price only after the item is added to their shopping cart would not deter automated price scraping but could make competitor price tracking more difficult.[128] They can and indeed do deny web scraping altogether, especially if it is determined that the scraping is being done by an algorithm. If firms do not want to wholesale-block information scraping by competitors (for example, when they are engaging in some kind of tacit or explicit collusion), they could in theory selectively change the information displayed depending on who is visiting, potentially defeating automated price monitoring.[129] That is, if algorithms can facilitate tacit collusion, there do not appear to be a strong a priori reason that technologies would not be able to facilitate deviation as well. Which of these incentives dominates is an empirical question.
III. Exploring Algorithmic Antitrust Compliance
Having explored the evidence of algorithmic collusion, we turn to another pertinent question: If pricing algorithms could autonomously collude, can they be made antitrust-compliant as well? Many have started pondering this after a series of public comments by EU competition officials in recent years. Explaining this concept, the EU Competition Commissioner Margrethe Vestager stated in a recent speech that “[w]hat businesses can—and must—do is to ensure antitrust compliance by design. That means pricing algorithms need to be built in a way that doesn’t allow them to collude.”[130] She later elaborated on her view at another conference: “[s]ome of these algorithms will have to go to law school before they are let out. You have to teach your algorithm what it can do and what it cannot do, because otherwise there is the risk that the algorithm will learn the tricks. . . . We don’t want the algorithms to learn the tricks of the old cartelists. . . . We want them to play by the book also when they start playing by themselves.”[131] Another senior EU official echoed the view that firms should program “software to avoid collusion in the first place”[132] and that “[r]espect for the rules must be part of the algorithm that a company configures and for whose behavior the company will be ultimately liable.”[133]
As desirable as antitrust compliance by design is, Simonetta Vezzoso pointed out that the implementation may not be straightforward: “[w]hile the idea of competition compliance by design might be gaining some foothold in the mind-sets of some competition authorities, there are currently no clear indications how it could be integrated into the already complex competition policy fabric.”[134] Indeed, what does it mean to “program compliance with the Sherman Act?” That is the question that Joseph Harrington asked in a recent paper. He concluded that all that the current jurisprudence tells us is to make sure algorithms do not “communicate with each other in the same sense that human managers are prohibited from communicating” under the Sherman Act.[135] But as both Vezzoso and Harrington suggested, there is more we could do.
In this section, I discuss several potential pathways to algorithmic compliance and argue that a robust compliance program should take a holistic and multi-faceted view. Specifically, I will look at a monitoring approach to compliance, then venture into the harder problem of designing compliant algorithms from the ground up. I will also discuss some existing proposals, draw additional lessons from the recent AI literature, and finally present potential technical frameworks, inspired by the current machine learning literature, for compliant algorithmic design.[136]
A. Algorithmic Compliance: A Monitoring Approach
The first approach is to use automated monitoring as a compliance tool. Despite not being the type of competition by design that would immediately come to mind, these algorithmic tools can be an important component of a compliance program. Instead of trying to dictate the design process, these tools monitor the behavior of humans as well as algorithms. The main advantage of this approach is that it does not attempt to open the black box of complicated computer programs; it focuses instead on the relevant firm behaviors that can be observed and interpreted.
Directly monitoring the “symptoms” of an antitrust violation is the most straightforward starting point. These “symptoms” are often referred to as plus factors or collusive markers. More formally, Kovacic, et al., define plus factors as “economic actions and outcomes, above and beyond parallel conduct by oligopolistic firms, that are largely inconsistent with unilateral conduct but largely consistent with explicitly coordinated action.” [137] They further define the super plus factors as the strongest of such factors. For example, unexplainable price increases or other types of abnormalities in prices have been recognized as such plus factors.[138] There is by now a robust “cartel screen” literature that studies empirical approaches and designs algorithms to detect such price anomalies.[139] And with adequate data and necessary analytical capabilities, empirical screening algorithms could be an important addition to an algorithmic compliance program.[140]
Michal Gal (2019) proposed several plus factors directly related to the use of pricing algorithms. For example, she argues that red flags should be raised if firms “consciously use similar algorithms even when better algorithms are available to them” or if “firms make conscious use of similar data on relevant market conditions even when better data sources exist,” among others.[141]
The second approach to algorithmic compliance has seen increasing adoption and success in the Regulatory Technology (RegTech) industry where AI technologies are being deployed to help companies meet their regulatory compliance needs. RegTech as an industry, often labelled as the new FinTech, or Financial Technology, has seen rapid growth in recent years.[142] Several RegTech companies currently offer AI-based compliance technologies based on natural language processing (NLP) and natural language understanding (NLU). According to one company, their NLP/NLU technology can “detect intentions, extract entities, and detect emotions” in human communications.[143] This type of technology could also be used to monitor communications among competitors to detect, and hence potentially deter, collusive behavior. Indeed, evidence of interfirm communications played a critical role in the investigation of a number of international cartel cases. With NLP and NLU AI technologies, machines can potentially flag problematic communications in real time in a cost-effective manner.
Despite the active and promising research in collusive markers and their uses for cartel detection and monitoring, developing these monitoring algorithms is by no means a trivial exercise. Collecting adequate and quality data is almost always the very first step. To the extent that a company or an antitrust agency wants to incorporate these tools in a compliance or a monitoring program, analytical capabilities may also be necessary.[144] Equally important to keep in mind is that findings of plus factors should typically lead to further investigation as there may be legitimate reasons for a specific conduct or market outcome.
B. Algorithmic Compliance: Compliance by Design
A much more challenging task is identifying specific algorithms or algorithmic features that should or should not be built in, a question that many may have in mind when thinking about compliance by design. But as discussed extensively above, existing AI research has given us many insights. Design features that have been exploited to achieve cooperation include the capability to communicate, use of a planning agent, modified objectives, and potentially other features guided by the answers to the questions posed by Leader– and Builder-type algorithms.
In the rest of this section, I discuss potential ways to implement compliance by design when we do not necessarily have knowledge about the problematic features beforehand or when it is difficult to isolate the properties that lead to supra-competitive pricing.
1. Looking Forward: A Research Proposal
Vezzoso highlighted the significant challenges in programming antitrust law directly into algorithms. She noted that “[p]rogrammers must articulate their objectives as ‘a list of instructions, written in one of a number of artificial languages intelligible to a computer’. . . . The flexibility of human interpretations, meaning the possibility that legal practitioners interpret norms and principles differently and that legal interpretation evolves over time, may conflict with the apparent stiffness of computer language. . . . The degree to which competition law is, or should be, suitable for automation is an interesting yet neglected topic.”[145] Indeed, given how concise the Sherman Act is, most legal scholars, if not all, would agree that turning the Sherman Act into a set of specific if-then type instructions is a tall order, if not outright impossible.
But here is what’s particularly interesting about how programmable antitrust laws are: The lack of (traditional) programmability is precisely the problem that modern machine learning and AI technologies are designed to circumvent. Consider the task of automatically recognizing and distinguishing cats and dogs in images. The traditional rule-based computer programming approach would be to enumerate all the physical differences between cats and dogs. But given how many subtle physical differences and similarities there are between cats and dogs, it gets difficult very quickly to improve classification accuracy. The standard (supervised) machine learning approach circumvents this problem by providing a large number of examples that consist of inputs (images) and associated outputs (the “label” describing whether the image is a cat or a dog) to a statistical model. A large number of such examples (i.e., training data) allows the model to search for the most predictive inputs, as well as the best way to map these inputs to the correct output, all without relying on rules that humans must painstakingly write down. This tells us that, perhaps, we also do not need to write down all the explicit instructions of antitrust compliance. Fortunately, economists and courts have identified a set of indicators predictive of collusive conduct. These are the plus factors I discussed above in the context of a monitoring approach to antitrust compliance. The question we address in this section is whether these predictors and the algorithms designed to monitor them can contribute directly to the design of antitrust-compliant algorithms, and if so, how.[146]
Before drawing inspirations from the existing AI literature, we should note that the first step of designing an algorithm is typically to specify its objective function. The most likely objective of a pricing algorithm is to maximize profit. But firms face various constraints when they maximize their profits. They may have limited capital or limited production capacity. There are also regulatory and ethical constraints on a firm’s pursuit of profits. Conceptually, antitrust compliance can be thought of as a similar constraint. Therefore, the technical challenge of compliance by design can be seen as one of implementing compliance as a constraint in the training/learning process of the algorithm.
Once we cast the technical challenge in this framework, several strands of AI literature offer inspiration for possible paths forward, allowing one to directly incorporate compliance into the algorithmic design. Intuitively, the so-called actor-critic approach relies on both an actor who tries to figure out a strategy that leads to the best outcome (e.g., highest profit) and a critic who examines the desirability (e.g., antitrust compliance) of an action dictated by the strategy given the circumstances, and provides the feedback to the actor for adjustment.[147] Generative adversarial networks (GANs), an intuitively similar idea, also draw strength from two algorithms. In this type of model, while one algorithm tries to generate some content (say, an image), the adversarial algorithm tries to identify it as a computer-generated fake.[148] A compliant pricing algorithm could have a similar actor-critic/adversarial structure in which, as the actor tries to maximize firm profit, the critic could look at a compliance score of a pricing decision taken by the actor and provide feedback so the actor could learn to steer away from problematic actions. The compliance score can take a variety of values to “discipline” the pricing algorithms. For example, the compliance score could be negative (i.e., a penalty) if, given the actions taken, cartel behaviors, such as collusive prices, arise at the end of the training; and the score could be positive if such evidence is absent. More sophisticated scoring methods could consider the strength of the plus factors as shown in the literature.[149] The compliance score may also be explicitly treated as a constraint in the pricing algorithm’s profit maximization problem, as in the statistical literature on regularization methods.[150] In these approaches, the compliance component is an integral part of the algorithm design.
I emphasize that even though these inspirations come from the existing literature, the conjectured approaches are nontrivial deviations from it. There are numerous technical and practical problems to be resolved and some ideas may not ultimately lead to the intended algorithmic behavior I conjectured here. For example, in a standard actor-critic approach, the ultimate objective of the two algorithms is typically the same, whereas in our conjectured application, the critic would adopt a very different objective. Another obvious challenge includes the proper ways of specifying the compliance score. Despite the aspirational nature of this discussion, the key takeaway is that the existing literature offers plausible paths forward for designing compliant pricing algorithms.
C. Explainable AI
Explainable AIs, especially those that can answer why and what-if questions, are another powerful tool in algorithmic antitrust compliance. To see why, suppose your pricing algorithm is setting a price that you think might be too high. A helpful what-if question could be, “What if we lower the price?” or “Would we generate higher immediate profit if we lower the price?” The answer might be, “Based on demand forecasts and our customers’ price elasticity, this is the optimal price we should set,” or “We have no reason to lower our price because we know that the competitor’s algorithm is not going to lower theirs, and we know that because we have determined that this is the best course of action that benefits both of us in the long term,” or even “We should not lower our price because the last time we lowered our price, the competitor started a price war.” Putting aside the question whether or not the last two responses suggest problematic algorithmic conduct, having this knowledge can be extremely helpful.
An AI study published in 2018 titled “Contrastive Explanations for Reinforcement Learning in Terms of Expected Consequences” is a step toward achieving the type of explainability discussed above.[151] In the framework of standard reinforcement learning, the researchers of the study developed a method that enables an RL agent to precisely answer the what-if questions similar to those we posed above. Another study titled “Explainable Reinforcement Learning Through a Causal Lens,” first published in 2019, proposed yet another approach to answering why and why not type questions.[152] Suppose we are curious about why the autonomous RL agent takes action A (say, raising prices to $X), instead of action B (say, setting a lower price of $Y). The researchers proposed an approach based on the comparison of the action A and the counterfactual action B to answer this why question.
It is important to keep in mind that multi-agent learning, the technology relevant to algorithmic collusion, is outside the scope of these particular AI research studies. It is safe to say, however, that it will be only a matter of time until we see progress in that area as well.
D. Other Approaches
Because RL algorithms learn through “trial and error” and are trained not to make the same mistakes and to exploit the correct decisions, even the simple protocol of documenting the learning process of the (pricing) algorithms can be helpful. If an algorithm is able to figure out on its own to use reward and punishment to elicit and sustain tacit collusion after the training phase, then the learning process should reflect that. Specifically, it will reflect how the payoffs changed as the algorithm adopted different actions and how the actions taken by the algorithm changed as a result.[153]
Some AI researchers have also proposed to label algorithms in much the same way as we label the nutrition facts on food items. These labels, or “model cards” as some researchers call them, would give information about the algorithms’ performance characteristics. In the context of ensuring ethical AI, researchers have recommended that model cards accompanying trained machine learning models provide benchmarked evaluation in a variety of conditions, “such as across different cultural, demographic, or phenotypic groups” and could “also disclose the context in which models are intended to be used, details of the performance evaluation procedures, and other relevant information.”[154] These ideas apply equally to pricing algorithms in an antitrust context. For example, the label for a pricing algorithm could clearly state whether the algorithm is equipped with communication or negotiation capabilities, and whether there is experimental evidence that the algorithm learns to tacitly collude with one another a la Calvano et al (2020).
Conclusion
Algorithms are becoming ubiquitous in our society. They are powerful and, in some cases, indispensable tools in today’s economy. In terms of the technology, we do not yet have AI sophisticated enough to, with a reasonable degree of certainty, reach autonomous tacit collusion in most real markets. This does not mean that we should ignore the potential risks. In fact, in their effort to design AIs that can learn to cooperate with each other and with humans for social good, AI researchers have shown that autonomous algorithmic coordination is possible. But there are also several positive takeaways from this research. For example, given the technical challenges, I argue that just like emails leave a trail of evidence when a cartel uses them to coordinate, a similar trail of evidence is likely present when collusive algorithms are being designed. The literature also gives us a good deal of insights about the types of design features and capabilities that could lead to algorithmic collusion. I highlighted the role of algorithmic communication as a leading example and argued that these known collusive features should raise red flags even if collusion is ultimately reached autonomously by algorithms.
The review of the recent economic literature in this chapter shows that the economic relationship between algorithms and collusion is subtle and likely market- and fact-specific. This makes a broad inference about the risk of algorithmic collusion difficult. Indeed, many have advocated for a prudent antitrust view toward the use of algorithms. Meanwhile, we have also just started seeing experimental evidence that algorithms can learn to collude even without being explicitly designed to do so. While this line of research is still at an early stage and has various limitations, further development in this area will enhance our understanding of the risk of algorithmic collusion. Of course, as Harrington (2019) and others have reminded us, it is always important that we evaluate both the pro- and anticompetitive effects of the algorithms so we do not exert unnecessary chilling effects on technological innovations.[155]
Given the lessons from the literature, from a corporate antitrust compliance perspective, it seems prudent for companies considering adopting strategic pricing algorithms to, at a minimum, ask: (1) how the algorithms increase their profitability to make sure that the promised profitability is not achieved through intended collusion, and (2) what information goes into the algorithms to make sure that the algorithms do not provide a back door for competitors to share sensitive information.[156]
I also explored the emerging topic of compliance by design, an intuitive yet nontrivial concept. As Vezzoso put it, “competition compliance by design can become an effective tool in the enforcer’s kit only if it is based on open, constructive and ongoing dialogues and exchanges with all interested stakeholders, including the enforcers themselves, firms, computer science experts, designers and providers of algorithms, academia, and consumers. Otherwise, a serious risk is that ‘competition by design’ remains an enticing slogan or, even worse, an ex-ante prophylactic measure.”[157] I attempted to fill some of the gaps identified by Vezzoso by presenting several potential pathways to algorithmic antitrust compliance. But there are many open questions and much to explore. It is my hope that this chapter stimulates more discussions and continued research on this important issue, one that is guaranteed to be increasingly relevant as we march forward in this fourth industrial revolution powered by constant AI advances.
Before closing, I want to highlight some recent economic studies that have identified novel ways in which algorithms could lead to supracompetitive prices. Hansen et al (2020) show that in an oligopolistic market, if demand is relatively deterministic, firms all behave as if they are monopolists (i.e., ignore the impact of competitors’ prices on their own profit) and run price experiments (as a way to determine the best price to charge) using certain algorithms, the resulting prices could be supracompetitive, leading to the concern that firms may willingly and purposefully adopt this mistaken view of market competition. The main intuition behind this result is that by behaving as a monopoly in an oligopolistic environment, firms over-estimate their own price sensitivity, resulting in higher prices. The researchers further show that in their framework, demand uncertainty (i.e., signal-to-noise ratio) is one of the key drivers of their finding: if demand is sufficiently random, then the resulting prices may be close to the competitive level.[158] Brown and MacKay (2019) show that if firms can choose their pricing frequency, then each firm has a unilateral profit incentive to choose a frequency different from those of their competitors. This again could lead to higher prices. The basic intuition is that “a superior-technology firm commits to ‘beat’ (best respond to) whatever price is offered by its rivals . . . The rivals take this into account, softening price competition.” Obviously, this result is true under their assumptions regardless of whether the price is set by algorithms or humans. But the authors argue that the use of pricing algorithms makes firms’ commitment to respond at given frequencies credible. [159] Finally, Harrington (2020) studies the effect of third-party pricing algorithms on competition. He found the interesting result that “third party design of a pricing algorithm can produce supracompetitive prices even when only one firm in the market adopts the pricing algorithm.” The key insights behind this finding are (1) the third-party’s objective to maximize the expected profit of an adopter and (2) the third-party’s recognition that their algorithm may face itself (i.e., adopted by others) in the market. Intuitively, these considerations lead the third-party developers to design an algorithm in a way that softens competition.[160] Overall, these studies have demonstrated more ways in which algorithms affect pricing well beyond algorithmic collusion of the “cooperate-or-punish” type and will undoubtedly generate additional interest as well as debates in the antitrust community for years to come.
With constant advances in technology and ever-increasing computation power, new ideas will undoubtedly continue to appear, update, and even revolutionize our understanding. I am optimistic that with the research by and collaboration among antitrust agencies, economists, and computer scientists, we will continue to improve our understanding of the economic underpinnings of algorithmic collusion and be positioned to tackle the associated risks and challenges.
Footnotes
* Ai Deng, PhD, is an Associate Director at NERA Economic Consulting and a lecturer at Johns Hopkins University. He can be reached at ai.deng@nera.com. The views expressed in this paper are those of the author and do not necessarily reflect the opinions of NERA or its clients, Johns Hopkins University, or its affiliates. The author thanks Joseph Harrington, Thibault Schrepel, Timothy Watts, and Ramsey Shehadeh for constructive comments on previous versions of the chapter. Matthew Lein, Miranda Isaacs, Griffin Jackson, Jocelyne Macias Oliveros, and Thomas McChesney provided excellent research and editorial assistance. All errors are mine.
[1] See Ariel Ezrachi & Maurice Stucke, Virtual Competition (2016).
[2] CPI Talks… Interview with Antonio Gomes of the OECD, CPI Antitrust Chron., May 2017, at 1, https://www.competitionpolicyinternational.com/cpi-talks-interview-with-antonio-gomes-of-the-oecd/.
[3] Obviously, there are many “ifs” in this stylized example as well as unanswered questions. For example, for the tacit collusion to be sustainable, the question whether the firms would at any point in time have incentive to deviate is a critical question.
[4] Maurice E. Stucke & Ariel Ezrachi, How Pricing Bots Could Form Cartels and Make Things More Expensive, Harv. Bus. Rev. (Oct. 27, 2016), http://governance40.com/wp-content/uploads/2018/11/How-Pricing-Bots-Could-Form-Cartels-and-Make-Things-More-Expensive.pdf.
[5] Michal Gal, Algorithmic-Facilitated Coordination: Market And Legal Solutions, CPI Antitrust Chron., May 2017, at 27.
[6] Dylan I. Ballard & Amar S. Naik, Algorithms, Artificial Intelligence, and Joint Conduct, CPI Antitrust Chron., May 2017, at 29.
[7] OECD Directorate for Financial and Enterprise Affairs, Competition Comm., Algorithms and Collusion 76, No. DAF/COMP(2017)4 (June 2017), https://one.oecd.org/document/DAF/COMP(2017)4/en/pdf.
[8] For example, Michal Gal discusses challenges for enforcers and potential countermeasures “when the algorithm employs machine learning based on neural networks, that is, it teaches itself the best way to behave in the market even if the coder did not model such conduct.” Gal, supra note 5, at 28.
[9] Nicolas Petit, Antitrust and Artificial Intelligence: A Research Agenda, 8 J. Eur. Competition L. & Pract. 361, 361–362 (2017).
[10] Salil K. Mehra, Robo-Seller Prosecutions and Antitrust’s Error-Cost Framework, CPI Antitrust Chron., May 2017, at 37.
[11] Axel Gautier, Ashwin Ittoo & Pieter Van Cleynenbreugel, AI Algorithms, Price Discrimination and Collusion: A Technical, Economic and Legal Perspective, Eur. J. L. Econ., July 14, 2020, at 26.
[12] Pallavi Guniganti, US DOJ Deputy: Algorithmic Cartel Requires Agreement, Glob. Competition Rev. (Feb. 5, 2018), https://globalcompetitionreview.com/us-doj-deputy-algorithmic-cartel-requires-agreement; see also U.S. Dep’t of Justice & Fed. Trade Comm’n, Algorithms and Collusion—Note by the United States 6 (Bkgd. Note for OECD Competition Cmte., May 26, 2017), https://one.oecd.org/document
/DAF/COMP/WD(2017)41/en/pdf:
Absent concerted action, independent adoption of the same or similar pricing algorithms is unlikely to lead to antitrust liability even if it makes interdependent pricing more likely. For example, if multiple competing firms unknowingly purchase the same software to set prices, and that software uses identical algorithms, this may effectively align the pricing strategies of all the market participants, even though they have reached no agreement.
[13] See Competition Bureau Canada, Big Data and Innovation: Key Themes for Competition Policy in Canada 10 (2017), http://www.competitionbureau.gc.ca/eic/site/cb-bc.nsf/vwapj/CB-Report-BigData-Eng.pdf/$file/CB-Report-BigData-Eng.pdf.
[14] Bundeskartellamt & Autorité de la Concurrence, Algorithms and Competition ii, (Nov. 2019), https://www.bundeskartellamt.de/SharedDocs/Publikation/EN/Berichte/Algorithms_and_Competition_Working-Paper.pdf?__blob=publicationFile&v=5.
[15] While we can broadly group many research studies under the umbrella of AI, the relevant literature is cross-disciplinary and involves game theory, experimental science, machine learning, and operational research.
[16] For a sample of the earlier literature, see, for example, Ulrich Schwalbe, Algorithms, Machine Learning, and Collusion, 14 J. Competition L. & Econ. 568 (2018); Ai Deng, What Do We Know About Algorithmic Tacit Collusion, 33 Antitrust 88 (2018); Steven Van Uytsel, Artificial Intelligence and Collusion: A Literature Overview, in Robotics, AI and the Future of Law, (M. Corrales et al., 2018); Gautier et al., supra note 11.
[17] Some scholars have highlighted the limited reach of existing antitrust law. Harrington, for example, writes:
Jurisprudence regarding Section 1 of the Sherman Act does not prohibit collusion . . . Effectively, what is illegal is communication among firms intended to achieve an agreement where an agreement is mutual understanding between firms to limit competition. Though the courts are clear in defining liability as an agreement, they are equally clear that there must be some overt act of communication to create or sustain that mutual understanding. . . . According to that jurisprudence, I claim that firms that collude through the use of AAs are not guilty of a Sherman Act Section 1 violation.
[emphasis added]. Joseph E. Harrington, Jr., Developing Competition Law for Collusion by Autonomous Artificial Agents, 14 J. Competition L. & Econ. 331, 346 (2019). For other examples, see Michal S. Gal, Algorithms as Illegal Agreements, 34 Berkeley Tech. L. J. 68 (2019); Maurice E. Stucke & Ariel Ezrachi, Sustainable and Unchallenged Algorithmic Tacit Collusion, 17 Nw. J. Tech. & Intell. Prop. 217 (2020).
[18] U.K. Competition & Mkts. Auth., Pricing Algorithms: Economic Working Paper on the Use of Algorithms to Facilitate Collusion and Personalized Pricing 44 (Working Paper No. CMA94, 2018), https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/746353/Algorithms_econ_report.pdf [hereinafter “CMA Report”]:
[W]e expect that there are likely to be relatively few retail markets in which there could be both explicit coordination and personalised pricing. Regardless of whether firms are using pricing algorithms, for both collusion and personalised pricing to coexist, all the ‘traditional’ conditions for both perfect price discrimination and collusion should be satisfied, and this is quite unlikely. In addition, we suspect that, particularly in retail markets, there may be a tension between a) the transparency and level of information needed to explicitly coordinate over many personalised prices, and b) the opacity needed to evade detection by competition authorities and to prevent customer resistance, particularly to personalised prices. There would need to be a very large asymmetry between cartelists and customers/regulators in technical ability and access to information about prices and transactions.
[19] This section draws heavily from Ai Deng, An Antitrust Lawyer’s Guide to Machine Learning, 33 Antitrust 82 (2018).
[20] Maureen K. Ohlhausen, Acting Chairman, Fed. Trade Comm’n, Should We Fear the Things That Go Beep in the Night? Some Initial Thoughts on the Intersection of Antitrust Law and Algorithmic Pricing (May 23, 2017), https://www.ftc.gov/system/files/documents/public_statements/1220893/ohlhausen_-_concurrences_5-23-17.pdf.
[21] Mitchell, T., Machine Learning 2 (1997).
[22] Stuart Russell & Peter Norvig, Artificial Intelligence: A Modern Approach 2 (3d ed. 2010).
[23] There is at least one other view about the difference between ML and AI. As Matt Taddy stated in an interview:
The terms “machine learning” and “artificial intelligence” are often used interchangeably. But there’s a distinction, and it’s an important one. Machine learning is largely restricted to predicting a future that looks like the past. In contrast, an artificial intelligence system is able to solve complex problems that have previously been reserved for humans.
Arun Krishnan, Business Data Science Is a Lot More Than Just Making Predictions, Amazon Sci. (Dec. 5, 2019), https://www.amazon.science/business-data-science-is-a-lot-more-than-just-making-predictions-matt-taddy.
[24] In fact, the analogy to human learning does not stop there. ML also makes heavy use of “test” data to “validate” what it learns about the problem.
[25] See, e.g., Am. Bar Ass’n, Econometrics: Legal, Practical, and Technical Issues (2d ed. 2014); see also Ai Deng, Book Review: Econometrics—Legal, Practical, and Technical Issues, 61 Antitrust Bull. 461, 461–66 (2016).
[26] For more details, see, for example, Predictive Coding (presentation for panel discussion at ABA Section of Litigation 2012 Section Annual Conference, (Apr. 2012), https://www.americanbar.org/content
/dam/aba/administrative/litigation/materials/sac_2012/14-1_predictive_coding_written_materials.
authcheckdam.pdf.
[27] For the readers familiar with regression analysis, the second chart is based on a simple logistic function. Of course, to be technically correct, nonlinearity pertains to model parameters, not the quantities themselves.
[28] “Therefore, by relying on deep learning, firms may be actually able to reach a collusive outcome without being aware of it, raising complex questions on whether any liability could ever be imposed on them should any infringement of the law be put in place by the deep learning algorithms.” OECD, supra note 7, at 79 (emphasis added).
[29] See Ai Deng, When Machines Learn to Collude: Lessons from a Recent AI Research (Sept. 2017) (unpublished manuscript), https://ssrn.com/abstract=3029662; see also Ai Deng, Four Reasons Why We Won’t See Colluding Robots Any Time Soon, Law360 (Oct. 3, 2017), https://www.law360.com/articles/970553/4-reasons-we-may-not-see-colluding-robots-anytime-soon.
[30] In a recent paper, Terrell McSweeny and Brian O’Dea discussed the implications of algorithmic price discrimination on antitrust market definition. See Terrell McSweeny & Brian O’Dea, The Implications of Algorithmic Pricing for Coordinated Effects Analysis and Price Discrimination Markets in Antitrust Enforcement, 32 Antitrust 75, 75–81 (2017). Gautier et al reviewed the latest AI and economic literature on algorithmic price discrimination and discussed policy implications. See Gautier et al, supra note 11.
[31] See Ai Deng, Cartel Detection and Monitoring: A Look Forward, 5 J. Antitrust Enf’t 488 (2017).
[32] Joseph E Harrington, Jr., Detecting Cartels, in Handbook of Antitrust Economics 213 (Paolo Buccirossi ed., 2008).
[33] A.G. Barto & T.G. Dietterich, Reinforcement Learning and Its Relationship to Supervised Learning, in Handbook of Learning and Approximate Dynamic Programming 47–64 (J. Si et al., eds., 2004).
[34] See Larry Greenemeier, AI Versus AI: Self-Taught AlphaGo Zero Vanquished Its Predecessor, Sci. Am., (Oct. 18, 2017), https://www.scientificamerican.com/article/ai-versus-ai-self-taught-alphago-zero-vanquishes-its-predecessor/.
[35] Ashwin Ittoo & Nicolas Petit, Algorithmic Pricing Agents and Tacit Collusion: A Technological Perspective (Oct. 2017), https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3046405.
[36] See also Finale Doshi-Velez & Been Kim, Towards A Rigorous Science of Interpretable Machine Learning 2 (Mar. 2, 2017) (unpublished manuscript), https://arxiv.org/abs/1702.08608.
[37] Explainable Artificial Intelligence (XAI), DARPA (Aug. 6, 2016), https://www.darpa.mil/program
/explainable-artificial-intelligence.
[38] See Will Knight, The Dark Secret at the Heart of AI, MIT Tech. Rev. (Apr. 11, 2017), https://www.technologyreview.com/s/604087/the-dark-secret-at-the-heart-of-ai/.
[39] See, e.g., Patrick Hall & Navdeep Gill, H2O.ai, An Introduction to Machine Learning Interpretability 3–4 (2019), https://www.h2o.ai/wp-content/uploads/2019/08/An-Introduction-to-Machine-Learning-Interpretability-Second-Edition.pdf; see also Joel Vaughan et al., Explainable Neural Networks based on Additive Index Models (June 5, 2018) (unpublished manuscript), https://arxiv.org/abs/1806.01933. Some scholars distinguish interpretability and explainability. For example, according to Cynthia Rudin, when we use a black box algorithm and explain it afterwards (post hoc), we are doing explainable machine learning while when we use a “white box” model to begin with, we are doing interpretable machine learning. Her view is that post hoc explainability is largely unhelpful. See Cynthia Rudin, Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead, 1 Nature Mach. Intell. 206, 206–215 (2019).
[40] This section draws heavily from Ai Deng, What Do We Know About Algorithmic Tacit Collusion?, 33 Antitrust, Fall 2018, at 88.
[41] Press Release, U.S. Dep’t of Justice, Former E-Commerce Executive Charged with Price Fixing in the Antitrust Division’s First Online Marketing Prosecution (Apr. 6, 2015), https://www.justice.gov/opa/pr/former-e-commerce-executive-charged-price-fixing-antitrust-divisions-first-online-marketplace:
According to the charge, Topkins and his co-conspirators agreed to fix the prices of certain posters sold in the United States through Amazon Marketplace. To implement their agreements, the defendant and his co-conspirators adopted specific pricing algorithms for the sale of certain posters with the goal of coordinating changes to their respective prices and wrote computer code that instructed algorithm-based software to set prices in conformity with this agreement.
Trod is a similar case. The UK CMA found that Trod Ltd and GB eye Limited conspired to not undercut each other’s prices. The agreement was also implemented by automated repricing tool. See Online Sales of Posters and Frames, Competition & Mkts. Auth. Cases (Dec. 4, 2015), https://www.gov.uk/cma-cases/online-sales-of-discretionary-consumer-products. Note also the recent OFGEM UK’s decision to fine energy suppliers for a market allocation agreement facilitated by software programs. U.K. Gas & Elec. Mkts Auth., Infringement by Economy Energy, E (Gas and Electricity) and Dyball Associates of Chapter I of the Competition Act 1998 with Respect to an Anti-Competitive Agreement (July 26, 2019), https://www.ofgem.gov.uk/publications-and-updates/decision-impose-financial-penalties-economy-energy-e-gas-and-electricity-and-dyball-associates-following-investigation-infringement-chapter-i-competition-act-1998.
[42] See, e.g, Jacob W. Crandall et al., Cooperating with Machines, Nature Commc’ns 2 (Jan. 16, 2018), https://www.nature.com/articles/s41467-017-02597-8:
The emergence of driverless cars, autonomous trading algorithms, and autonomous drone technologies highlight a larger trend in which artificial intelligence (AI) is enabling machines to autonomously carry out complex tasks on behalf of their human stakeholders. To effectively represent their stakeholders in many tasks, these autonomous machines must interact with other people and machines that do not fully share the same goals and preferences. While the majority of AI milestones have focused on developing human-level wherewithal to compete with people or to interact with people as teammates that share a common goal, many scenarios in which AI must interact with people and other machines are neither zero-sum nor common-interest interactions. As such, AI must also have the ability to cooperate even in the midst of conflicting interests and threats of being exploited.
See also Jakob N. Foerster et al., Learning with Opponent-Learning Awareness 1 (Sep. 19, 2018) (unpublished manuscript), https://arxiv.org/abs/1709.04326:
The human ability to maintain cooperation in a variety of complex social settings has been vital for the success of human societies. Emergent reciprocity has been observed even in strongly adversarial settings such as wars, making it a quintessential and robust feature of human life. In the future, artificial learning agents are likely to take an active part in human society, interacting both with other learning agents and humans in complex partially competitive settings. Failing to develop learning algorithms that lead to emergent reciprocity in these artificial agents would lead to disastrous outcomes.
[43] For a well-cited study, see Robert M. Axelrod, The Evolution of Cooperation (1984).
[44] Furthermore, unless the products are completely homogeneous and firms have identical costs, firms may not find copying competitors’ pricing from the last period desirable. Equally important is that theoretically, it is known that TFT is not a robust strategy. There is much discussion on the weaknesses of TFT in the literature. For example, a single mistake in either party’s action could lead to a “death spiral.” That is, when one party defects while the opponent cooperates in just one period, the parties will end up alternating between cooperation and defection, yielding worse payoff for both than if they had cooperated.
[45] See Crandall et al., supra note 42. Examples of these messages include proposals to take a certain action (e.g., cooperate), threats (e.g., “do as I say, or I’ll punish you”) as well as either positive or negative reactions (e.g., “You betrayed me” and “Sweet. We are getting rich”). Jacob W. Crandall et al., Cooperating with Machines (Supplementary Table 21), Nature Commc’ns 2 (Jan. 16, 2018), https://static-content.springer.com/esm/art%3A10.1038%2Fs41467-017-02597- 8/MediaObjects/41467_2017_2597_MOESM1_ESM.pdf. For an in-depth discussion of the lessons one could draw from this study on algorithmic collusion, see Deng, supra note 29.
[46] “Finally, the somewhat non-conventional expert-selection mechanism used by S# (see Eq. 1 in Methods) is central to its success. . . . Given the same full, rich set of experts, more traditional expert-selection mechanisms establish effective relationships in far fewer scenarios than S#.” Jacob W. Crandall et al., Cooperating with Machines, Nature Commc’ns (Jan. 16, 2018), https://www.nature.com/articles/s41467-017-02597-8.
[47] See Adam Lerer & Alexander Peysakhovich, Maintaining Cooperation in Complex Social Dilemmas Using Deep Reinforcement Learning (Mar. 2, 2018) (unpublished manuscript), https://arxiv.org/abs/1707.01068 [hereinafter Maintaining Cooperation]; see also Alexander Peysakhovich & Adam Lerer, Consequentialist Conditional Cooperation in Social Dilemmas with Imperfect Information, Procs Int’l Conf. on Learning Representations (Mar. 2, 2018), https://arxiv.org/abs/1710.06975 [hereinafter Consequentialist Conditional Cooperation].
[48] See Tobias Baumann, Thore Graepel & John Shawe-Taylor, Adaptive Mechanism Design: Learning to Promote Cooperation (Nov. 20, 2019) (unpublished manuscript), https://arxiv.org/abs/1806.04067. For a definition of a hub and spoke conspiracy, see U.S. Dep’t of Justice & Fed. Trade Comm’n, Hub-and-Spoke Arrangements—Note by the United States 2 (Bkgd. Note for OECD Competition Cmte., Nov. 28, 2019), https://www.ftc.gov/system/files/attachments/us-submissions-oecd-2010-present-other-international-competition-fora/oecd-hub_and_spoke_arrangements_us.pdf:
In United States antitrust law, a ‘hub and spoke conspiracy’ is a term of art used to describe horizontal conspiracies that include participants who are in a vertical relationship with one or more of the competitor conspirators. The conspiracy is organized so that one level of a supply chain—a buyer or supplier—acts like the ‘hub’ of a wheel. Vertical relationships up or down the supply chain act as the ‘spokes’ and, most importantly, a horizontal agreement among the spokes acts as the “rim” of the wheel. The distinguishing feature of a hub and spoke conspiracy is the participation of the vertically aligned conspirator in the horizontal agreement.
[49] See Foerster et al, supra note 42, at 1.
[50] Pinkesh Badjatiya et al., Inducing Cooperative Behaviour in Sequential-Social Dilemmas Through Multi-Agent Reinforcement Learning Using Status-Quo Loss 2, 9 (Feb. 13, 2020) (unpublished manuscript), https://arxiv.org/pdf/2001.05458.pdf.
[51] Id. at 2.
[52] Alexis Jacq et al., Foolproof Cooperative Learning 1 (Sep. 5, 2019) (unpublished manuscript), https://arxiv.org/abs/1906.09831.
[53] Id. at 1 (emphasis added).
[54] As Harrington noted, “[A]ctual markets are far more complicated than the stark simplicity of the Prisoners’ Dilemma. Actual markets have many possible prices to be selected for multiple products, and firms that are subject to changes in cost and demand.” Joseph E. Harrington, Jr., Developing Competition Law for Collusion by Autonomous Price-Setting Agents 20 (Aug. 22, 2017) (unpublished manuscript), https://ssrn.com/abstract=3037818. This is an earlier manuscript of Harrington, supra note 17.
[55] Note that some studies assume that the AI agents are not aware of the payoffs but rather have to learn about them in the process. So, the assumption of fixed payoffs is distinct from the assumption regarding the information set of the AI agents.
[56] For example, Green and Porter show that under such conditions, one way for the cartel to sustain its agreement is to agree to revert to competition if the market price falls below a certain level (known as a “trigger price”), as a way to “punish” potential cheaters and reduce the incentive to cheat. Clearly, a price war may simply be triggered because the demand is weak (hence lower prices) but not because of cheating. More generally, economists have argued that demand volatility tends to hinder collusion. See, Edward J. Green & Robert H. Porter, Noncooperative Collusion under Imperfect Price Information, 52 Econometrica 87 (1984); Robert H. Porter, A Study of Cartel Stability: The Joint Executive Committee, 1880–1886, 14 Bell J. Econ. 301 (1983). In Rotemberg and Saloner’s model, a positive demand shock (e.g., an economic boom) could disrupt collusion by increasing firms’ incentive to deviate from their agreement because they could profit more from the high demand by doing so (say, by lowering prices). Julio J. Rotemberg & Garth Saloner, A Supergame-Theoretic Model of Business Cycles and Price Wars During Booms, 76 Am. Econ. Rev. 390 (1986); G. Ellison, Theories of Cartel Stability and the Joint Executive Committee, 25 RAND J. Econ. 37 (1994).
[57] This situation is known as the “Nash equilibrium” in game theory. There are also many “refinements” to Nash equilibria, some of which are designed to be even more robust and stable.
[58] Peysakhovich and Lerer explicitly make this distinction:
[T]he question of designing a good agent for social dilemmas can sometimes be quite different from questions about computing equilibrium strategies. For example, in the repeated PD, tit-for-tat is held up as a good strategy for an agent to commit to (Axelrod, 2006). However, both players using tit-for-tat is not an equilibrium (since the best response to tit-for-tat is always cooperate).
Lerer & Peysakhovich, Consequentialist Conditional Cooperation, supra note 47, at 2. In fact, it is clear that one of their designs, the so-called amTFT, is not an equilibrium strategy based on their Figure 5.
[59] See Foerster et al., supra note 42, at 8.
[60] See, e.g., Susan Athey, Kyle Bagwell & Chris Sanchirico, Collusion and Price Rigidity, 71 Rev. Econ. Stud. 317, (2004); see also Jeanine Miklos-Thal, Optimal Collusion Under Cost Asymmetry, 46 Econ. theory 99, 99-125 (2011).
[61] Crandall et al., supra note 45, at 2.
[62] Crandall et al., supra note 45, at 2.
[63] Jacob W. Crandall & Michael A. Goodrich, Learning to Compete, Coordinate, And Cooperate in Repeated Games Using Reinforcement Learning, 82 Mach. Learning 281, 281–314 (2011), p.281.
[64] Jacob W. Crandall, When Autonomous Agents Model Other Agents: An Appeal for Altered Judgment Coupled with Mouths, Ears, And A Little More Tape, 280 A.I. 103219, Dec. 16, 2019, at 1.
[65] But what are the chances that a collusive algorithmic feature is also procompetitive (that is, efficiency enhancing)? Harrington (2019) concluded that the “properties of pricing algorithms that deliver these efficiencies are not directly relevant to generating collusion.” Harrington, supra note 17, at 24. Anticipating an imperfect delineation, Harrington also proposed a framework to assess the antitrust liability of a particular algorithm to the extent that there is some uncertainty. See id.
[66] The joint French and German report provides a more detailed discussion. Bundeskartellamt & Autorité de la Concurrence, supra note 14, at 68–74.
[67] This is important because there is a natural and understandable “fear” of complex AI/ML methods such as deep neural networks. For example, Stucke and Ezrachi emphasize,
We note how, to date, most strategies discussed are powered by price algorithms and are yet to include cutting-edge neural networks. The increased use of neural networks will indeed complicate enforcement efforts. . . . Due to their complex nature and evolving abilities when trained with additional data, auditing these networks may prove futile. The knowledge acquired by a Deep Learning network is diffused across its large number of neurons and their interconnections, analogous to how memory is encoded in the human brain. These networks, based on non-linear transformations, are considered as opaque, black boxes. Enforcers may lack the ability to trace back the steps taken by algorithms and unravel the self-learning processes. If deciphering the decision making of a deep learning network proves difficult, then identifying an anticompetitive purpose may be impossible.
Ariel Ezrachi & Maurice E. Stucke, Algorithmic Collusion: Problems and Countermeasures 17, 26 (Bkgd. Note for OECD Competition Cmte., May 31, 2017), https://www.oecd.org/officialdocuments
/publicdisplaydocumentpdf/?cote=DAF/COMP/WD%282017%2925&docLanguage=En.
[68] Here, I treat the literature on algorithmic collusion somewhat distinctively from the large experimental literature in economics that studies human behavior in oligopolistic markets. For an example in the latter literature, see Steffen Huck, Hans-Theo Normann & Jörg Oechssler, Two Are Few and Four Are Many: Number Effects in Experimental Oligopolies, 53 J. Econ. Behav. Org. 435 (2004).
[69] Nan Zhou et al, Algorithmic Collusion in Cournot Duopoly Market: Evidence from Experimental Economics (Feb. 21, 2018) (unpublished manuscript), https://arxiv.org/abs/1802.08061.
[70] See William H. Press & Freeman J. Dyson, Iterated Prisoner’s Dilemma Contains Strategies That Dominate Any Evolutionary Opponent, 109 Procs. Nat’l Acad. Sci. 10409, 10409 (2012).
[71] See Ludo Waltman & Uzay Kaymak, Q-Learning Agents in a Cournot Oligopoly Model, 32 J. Econ.
Dynamics & Control 3275, 3287 (2008). For a user-friendly introduction to Q-learning, see Ittoo & Petit, supra note 35. Note that the Foolproof Cooperative Learning developed by Jacq et al. (2019) also uses Q-learning. See Jacq et al., supra note 52.
[72] See Emilio Calvano et al., Algorithmic Pricing and Collusion: What Implications for Competition Policy?, 55 Rev. Indus. Org. 155 (2019).
[73] For a discussion on the implausibility of “accidental tacit collusion” or “blundering into tacit collusion,” see, for example, Edward J. Green, Robert C. Marshall & Leslie M. Marx, 2, Tacit Collusion in Oligopoly, in Oxford Handbook Int’l Antitrust Econ. (Roger D. Blair & D. Daniel Sokol eds., 2014).
[74] Emilio Calvano et al., Artificial Intelligence, Algorithmic Pricing and Collusion, Am. Econ. Rev. (forthcoming 2020) (manuscript at 1), https://ssrn.com/abstract=3304991.
[75] To show this, the researchers forced their algorithm to “cheat” in one period by lowering its own price. They found that the competitor would immediately lower its price in the next period by even a larger amount, suggesting a “punishment.” What is also interesting is that it appears that the “cheating” algorithm anticipates the punishment because it also immediately lowers its price. After that, the researchers find that both algorithms gradually raise their price to a pre-cheating supra-competitive level in almost lock-steps.
[76] See, e.g., Harrington, supra note 17, at 6 (“Definition: Collusion is when firms use strategies that embody a reward–punishment scheme which rewards a firm for abiding by the supracompetitive outcome and punishes it for departing from it.”); see also Alexander Peysakhovich & Adam Lerer, Towards AI That Can Solve Social Dilemmas 5, Ass’n for Advancement A.I. (Mar. 15, 2018), https://www.aaai.org/ocs/index.php/SSS/SSS18/paper/view/17560/15514 (“Any conditionally cooperative strategy needs access to the cooperative strategy and a ‘threat’ strategy.”).
[77] See Ittoo & Petit, supra note 35 (discussing additional technical challenges related to RL).
[78] For additional commentary on this study and suggested future research topics, see Ai Deng, Algorithmic Tacit Collusion is a Limited Threat to Competition, Law360 (Dec. 10, 2019), https://www.law360.
com/articles/1226694/algorithmic-tacit-collusion-is-a-limited-threat-to-competition.
[79] Under the learning parameters considered by the researchers, the learning can take as short as 400,000 and as long as up to 2.5 million periods. See Calvano et al., supra note 74, at 18.
[80] In their baseline experiment, the researchers allow only 15 different choices. Id. at 21.
[81] “The downside of such relatively simple AI technology is the slowness of learning. But this is not a problem as long as one focuses on the behavior of the algorithm once they have competed the training process. This paper takes precisely such off-the-job approach. That is, we conform to the standard practice of training the algorithm before assessing their performance.” Calvano et al., supra note 74, at 12.
[82] See Timo Klein, Autonomous Algorithmic Collusion: Q-Learning Under Sequential Pricing 34 (Amsterdam L. Sch. Rsch. Paper No. 2018-15, 2019), https://ssrn.com/abstract=3195812. The author considered the situation where both competitors use Q-learning algorithms as well as the situation where one uses Q-learning and other uses the tit-for-tat strategy. My discussion here is limited to the baseline results pertaining to Q-learning vs. Q-learning. Klein’s work also extended an earlier paper by Tesauro & Kephart (2002) that assumed the algorithms have full knowledge of the environment. See Gerald Tesauro & Jeffrey O. Kephart, Pricing in Agent Economies Using Multi-Agent Q-Learning, 5 Autonomous Agents & Multi-Agent Sys. 289, 292–93 (2002).
[83] “For those runs where both algorithms are playing best response to each other, Figure 3 lower panel shows the joint distribution of profitabilities Qi. It shows that a Nash equilibrium is reached in 312 runs for k = 6, 79 runs for k = 12 and only 10 runs for k = 24.” Klein, pp. 18-19, supra note 82. Note that the number of possible prices is equal to k+1. Klein, supra note 82, at 7.
[84] “Results are shown for those runs in which the algorithms managed to coordinate on a Nash equilibrium with joint-profit maximizing prices in case of k = 6 (135 runs) and with at most one price increment away from joint-profit maximizing prices in case of k = 12 (19 runs).” Id. at 21.
[85] Id. at 32.
[86] Id. at 34.
[87] See Bruno Salcedo, Pricing Algorithms and Tacit Collusion (Nov. 11, 2015) (unpublished manuscript), http://brunosalcedo.com/docs/collusion.pdf.
[88] And all these are also common knowledge among the competitors.
[89] See Schwalbe, supra note 16, at 590 (“It should be noted, however, that such collusion is not tacit, as the title of Salcedo’s (2015) paper suggests, but involves direct communication between the firms through the decoding of an algorithm and is thus equivalent to explicit collusion between the firms.”).
[90] Bundeskartellamt & Autorité de la Concurrence, Competition Law and Data 14 (2016), https://www.bundeskartellamt.de/SharedDocs/Publikation/DE/Berichte/Big%20Data%20Papier.html.
[91] Bundeskartellamt & Autorité de la Concurrence, supra note 14, at 18.
[92] Francisco Beneke & Mark-Oliver Mackenrodt, Artificial Intelligence and Collusion, 50 Int’l Rev. Intell. Prop. & Competition L. 109, 126 (2019).
[94] See Joseph. E. Harrington, Jr., How Do Cartels Operate?, 2 Founds. & Trends Microecon. 1, 53–54 (2006).
[95] See Takuo Sugaya & Alexander Wolitzky, Maintaining Privacy in Cartels, 126(6) J. Pol. Econ. 2569, 2600 (2018).
[96] Jeanine Miklos-Thal & Catherine Tucker, Collusion by Algorithm: Does Better Demand Prediction Facilitate Coordination Between Sellers? 65 Mgmt. Sci. 1455, 1552 (2019).
[97] Id. at 1552.
[98] See Jason O’Connor & Nathan E. Wilson, Reduced Demand Uncertainty and the Sustainability of Collusion: How AI Could Affect Competition, Info. Econ. & Pol’y (forthcoming 2020).
[99] Sugaya & Wolitzky, Supra note 95.
[100] Michal S. Gal, Algorithmic-facilitated Coordination—Note by Michal Gal 26 (Bkgd. Note to Competition Cmte., June 22, 2017), https://one.oecd.org/document/DAF/COMP/WD(2017)26/en/pdf.
[101] OECD, Algorithms and Collusion: Competition Policy in the Digital Age 22 (2017), www.oecd.org/competition/algorithms-collusion-competition-policy-in-the-digital-age.htm.
[102] Beneke & Mackenrodt, supra note 92, at 126.
[103] See Yuliy Sannikov & Andrzej Skrzypacz, Impossibility of Collusion under Imperfect Monitoring with Flexible Production, 97 Am. Econ. Rev. 1794, 1814 (2007).
[104] Cf. Maria Bigoni et al, Frequency of Interaction, Communication and Collusion: An Experiment, 68 Econ. Theory 827 (2018). Specifically, the authors find a U-shaped relationship between the speed of reaction and collusion. Subjects in their experiments were able to sustain collusion the longest when the speed of their reaction is intermediate. Interestingly, the authors also find that communication is the key to successful collusion and the speed of their reaction has only a secondary effect.
[105] See David Rahman, Information Delay in Games with Frequent Actions i (June 23, 2013) (unpublished manuscript), https://87b2a7c5-a-62cb3a1a-s-sites.googlegroups.com/site/davidrahmanwork/delay.pdf?
attachauth=ANoY7comvISCkGGlk2n1o6YMhD7VfA1Lg31ICZdNcMyLE5hU55uLB66KIX5rE1w6YNxtz4lipZqZclVtyO7nSOQdn7kXkY-nYk7-o2e6b2mf4YroH4PXFrNPkpnPCH9IL0-c3_Dcz-LqIPw1VKgs5ToUFX4Jg-OS. (“I study repeated games with frequent actions and obtain a Folk Theorem in strongly symmetric strategies for the Prisoners’ Dilemma if public information can be delayed.” (emphasis added)).
[106] It is worth noting that some have also argued that this theoretical result is largely driven by certain assumptions made previously. See, e.g., António M. Osório, A Folk Theorem for Games When Frequent Monitoring Decreases Noise, 12 B.E.J. Theoretical Econ. 1 (2012).
[107] See OECD, supra note 101, at 23.
[108] See, e.g., Jeanine Miklos-Thal, supra note 60, at 1 (“Cost asymmetry is generally thought to hinder collusion”). But see David P. Byrne & Nicolas De Roos, Learning to Coordinate: A Study in Retail Gasoline, 109 Am. Econ. Rev. 591, 618 (2019) (“[M]ergers that generate asymmetric firms may also facilitate collusion by enabling price leadership and experimentation.”).
[109] Marc Ivaldi et al., The Economics of Tacit Collusion 36 (IDEI, Working Paper No. 186, Mar. 2003), http://idei.fr/sites/default/files/medias/doc/wp/2003/tacit_collusion.pdf.
[110] See CMA Report, supra note 18, at 15:
[C]ompetition authorities could also examine whether the algorithm can place weight on or value future profits. If the algorithm’s objective function is very short-term (e.g. maximise profit on each and every sale, with no regard for the impact of its current actions on future profits) then the algorithm is less likely to lead to coordination.
[111] Natalie Taylor, Know Your Competition: How to Increase Sales on Amazon, Feedvisor (Aug. 30, 2019), https://feedvisor.com/resources/e-commerce-strategies/know-your-competition-how-to-increase-sales-on-amazon-webinar-recap/.
[112] Not surprisingly, the capability to communicate by itself is not sufficient to develop an effective cooperative algorithm. Algorithms will also need to know how to best respond to communications. This is particularly important when AI agents’ self-interests diverge as in PDs and in competitive marketplaces. For an overview, see Angeliki Lazaridou & Marco Baroni, Emergent Multi-Agent Communication in the Deep Learning Era, (Jul. 14, 2020) (unpublished manuscript), https://arxiv.org/abs/2006.02419.
[113] Crandall, supra note 64, at 2.
[114] Id. at 8.
[115] Id. at 9.
[116] See, e.g., Cédric Buron et al., MCTS-based Automated Negotiation Agent, Int’l Conf. on Principles & Prac. Multi-Agent Sys. (Sept. 23, 2019), https://arxiv.org/abs/1909.09461; Tim Baarslag et al., A Survey of Opponent Modeling Techniques in Automated Negotiation (AAMAS Working Paper, May 2016), https://eprints.soton.ac.uk/393780/; Tim Baarslag et al., A Tit for Tat Negotiation Strategy for Real-Time Bilateral Negotiations, in Complex Automated Negotiations: Theories, Models, and Software Competitions 229 (Takayuki Ito et al. eds., 2013).
[117] See, e.g., Paula Chocron & Marco Schorlemmer, Vocabulary Alignment in Openly Specified Interactions, 68 J.A.I. Rsch. 69 (2020); see also research on natural language generation (NLG), for example, Will Douglas Heaven, OpenAI’s New Language Generator GPT-3 Is Shockingly Good – and Completely Mindless, MIT Tech. Rev. (July 20, 2020), https://www.technologyreview.com/2020/07/20/1005454/openai-machine-learning-language-generator-gpt-3-nlp/.
[118] This is consistent with the point made by Harrington (2019). He writes that “AAs would not be in compliance if they coordinated their conduct using arbitrary messages unrelated to the competitive process . . . .” Harrington, supra note 17, at 19.
[119] See Gautier et al., supra note 11 (identifying such algorithmic designs as examples of the so-called predictable agent scheme).
[120] AI researchers have recognized that doing so is a natural starting point for designing AIs that can learn to cooperate (“A natural desiderata then is to ask for agents in complex social dilemmas that maintain the good properties of these well-known PD strategies.”) Peysakhovich & Lerer, Towards AI that Can Solve Social Dilemmas, 2018 AAAI Spring Symposium Series; see also Zhou et al., supra note 69.
[121] Ezrachi & Stucke, supra note 67, at 28.
[122] See Harrington, supra note 17, at 356–58.
[123] Crandall, supra note 64, at 4–5.
[124] Id. at 5.
[125] I focus on the potential risks of collusion in this section. Algorithms obviously have many positive and pro-competitive effects on digital markets. See, e.g., Thibault Schrepel & Michal S. Gal, Algorithms & Competition Law: Interview of Michal Gal by Thibault Schrepel, Concurrences (May 14, 2020). https://www.concurrences.com/en/bulletin/special-issues/algorithms/algorithms-competition-law-prof-michal-gal-s-interview-about-eu-and-national-en; CMA Report, supra note 18, at 20–31, 47–51.
[126] CMA report, supra note 18, at 13; see also OECD, supra note 7, at 5.
[127] Schwalbe, supra note 16, at 154.
[128] I note that the current practice of not displaying prices until after the item is added to one’s cart is likely largely driven by the minimum advertised price (MAP) requirement.
[129] See, e.g., U.S. Patent No. 8,595,847 col. 3 ll. 48–53 (issued Nov. 26, 2013) (“If the requester is determined to be a bot, the web server may selectively provide or not provide certain information/content of the web page. For example, when a web page is visited by a bot of a search engine, dynamic content and graphical contents and/or advertisements may not be presented, while relevant keywords can be added.”). Firms may also use technology to circumvent such restrictions (say, with the use of VPN).
[130] Margrethe Vestager, Comm’r for Competition, Eur. Comm’n, Algorithms and Competition: Speech at the Bundeskartellamt 18th Conference on Competition, Berlin (Mar. 16, 2017), https://wayback.archive-it.org/12090/20191129221651/https://ec.europa.eu/commission/commissioners/2014-2019/vestager/announcements/bundeskartellamt-18th-conference-competition-berlin-16-march-2017_en.
[131] Recode, Web Summit in Lisbon – Interview of Commissioner Vestager (Competition) by Kara Swisher (Recode), YouTube (Nov. 6, 2017), https://youtu.be/90OhCfyYOOk.
[132] Johannes Laitenberger, Dir.-Gen., DG-Comp, Competition at the Digital Frontier: Speech at the Consumer and Competition Day (Apr. 24, 2017), http://ec.europa.eu/competition
/speeches/text/sp2017_06_en.pdf.
[133] Johannes Laitenberger, Dir.-Gen., DG-Comp, Level and Open Markets Are Good for Business: Speech at the AMCHAM-EU 34th Annual Competition Policy Conference (Oct. 27, 2017), https://ec.europa.eu/
competition/speeches/text/sp2017_19_en.pdf.
[134] Simonetta Vezzoso, Competition by Design 1 (Nov. 28, 2017) (unpublished manuscript), https://ssrn.com/abstract=2986440.
[135] Harrington, supra note 17, at 348–49.
[136] For readers interested in legal implications and current proposals, see references supra note 17. I also do not discuss the use of algorithms by consumers to combat algorithmic collusion. This is the idea of algorithmic consumers proposed by Michal S. Gal and Niva Elkin-Koren. See Michal S. Gal & Niva Elkin-Koren, Algorithmic Consumers, 30 Harv. J.L. & Tech. 309 (2017).
[137] William E. Kovacic et al., Plus Factors and Agreement in Antitrust Law, 110 Mich. L. Rev. 393, 393 (2011).
[138] Id. at 393.
[139] For a review and a discussion about future research areas in this literature, see Deng, supra note 31.
[140] While almost never made explicit, it is worth noting that almost all the current discussions in the antitrust community are limited to price-setting algorithms. Obviously, cartels and cartel agreements come in different shapes and forms. Some cartels fix prices, while others allocate markets or rig bids. Some cartels use list pricing, while others mainly rely on sales representatives, with or without list prices. Depending on the nature of the cartel, the ways to implement an agreement, tacit or explicit, are also going to be different. And as a result, the types of collusive markers may also be different.
[141] Gal, supra note 16, at 114. When considering these factors, it is important to keep in mind that better algorithms and better data may be more costly to the firms, which might explain firms’ choices.
[142] Deloitte curates a list of RegTech companies and, as of August 16th, 2020, there are 378 companies on the list. See RegTech Universe 2020, Deloitte, https://www2.deloitte.com/lu/en/pages/technology/
articles/regtech-companies-compliance.html (last visited Aug. 16, 2020). Eighty percent of these companies were started in the past 10 years. Companies started in the five-year span between 2012 and 2016 account for over 60% of all RegTech firms. The UK Financial Conduct Authority is also actively looking to RegTech. See Alison Noon, UK Finance Cop ‘Aggressively’ Pursuing Robo Regulation, Law360, (Jan. 17 2019), https://www.law360.com/articles/1119869/uk-finance-cop-aggressively-pursuing-robo-regulation.
[143] Success Stories, Fonetic, https://fonetic.com/en/success-stories/ (last visited Sept. 23, 2020).
[144] Careful implementation of these tools is also critical. For a discussion of some of the analytical pitfalls, see Deng, supra note 31.
[145] Vezzoso, supra note 134, at 26.
[146] As I alluded to earlier, it is important to keep in mind that plus factors/collusive markers are indirect proof of collusion and their predictive power typically depends on market facts and other factors.
[147] See, e.g., Kai Arulkumaran et al., Deep Reinforcement Learning: A Brief Survey, 34 IEEE Signal Processing Mag. 26 (2017), https://ieeexplore.ieee.org/abstract/document/8103164.
[148] See Ian J. Goodfellow et al., Generative Adversarial Networks, (June 10, 2014) (unpublished manuscript), https://arxiv.org/abs/1406.2661. Facebook’s AI research director Yann LeCun called adversarial training “the most interesting idea in the last 10 years in [machine learning].” Yann LeCun, Quora (July 28, 2016), https://www.quora.com/What-are-some-recent-and-potentially-upcoming-breakthroughs-in-deep-learning.
[149] See, e.g., Kovacic, et al., 2011, supra note 137.
[150] For readers with a technical background, regularization methods are closely related to the concept of “shrinkage.” The basic idea behind this type of approach is to introduce constraints on model parameters. For an example of how regularization may be used to balance different modeling objectives, see Mohammad Taha Bahadori et al., Causal Regularization, (Feb. 23, 2017) (unpublished manuscript), https://arxiv.org/abs/1702.02604.
[151] J. van der Waa et al., Contrastive Explanations for Reinforcement Learning in Terms of Expected Consequences, 37 IJCAI-18 Workshop on Explainable A.I. (2018) https://arxiv.org/pdf/1807.08706.pdf.
[152] See Prashan Madumal et al., Explainable Reinforcement Learning through a Causal Lens, 34 Procs. AAAI Conf. on A.I. 2493 (2020), https://aaai.org/ojs/index.php/AAAI/article/view/5631.
[153] This is also related to a point made by Harrington, supra note 17, at 20 (“When prices are controlled by an autonomous artificial agent, the firm’s strategy is, in principle, observable. . . .And if one can observe the strategy, then one can determine whether it embodies a reward–punishment scheme, which is the defining feature of collusion, what results in supracompetitive prices, and what should be prohibited.”).
[154] Margaret Mitchell et al, Model Cards for Model Reporting 1, FAT* ’19: Conf. on Fairness, Accountability, & Transparency (Jan. 14, 2019), https://arxiv.org/abs/1810.03993; see also Julia Stoyanovich & Bill Howe, Nutritional Labels for Data and Models, Bull. IEEE Comp. Soc’y Tech. Comm. Data Eng’g, 2019, at 13, http://sites.computer.org/debull/A19sept/p13.pdf; Julia Stoyanovich, et al, The Imperative of Interpretable Machines, 2 Nature Mach. Intell. 197 (2019).
[155] For example, the interaction between (procompetitive) algorithmic price discrimination and the risks of algorithmic collusion is an important subject that deserves a closer look.
[156] In addition, research on “collusion incubator” and along the lines proposed by Ezrachi and Stucke, supra note 67, and Harrington, supra note 67, could potentially allow one to “audit” (self-learning) algorithms.
[157] Vezzoso, supra note 134, at 30.
[158] See Hansen Karsten et al., Algorithmic Collusion: Supra-Competitive Prices Via Independent Algorithms 11–12 (CEPR Discussion Paper No. DP14372, 2020), https://repec.cepr.org/repec/cpr/ceprdp/DP14372.pdf. See an early but similar result by William L. Cooper, Tito Homen-de-Mello & Anton J. Kleywegt, Learning and Pricing with Models That Do Not Explicitly Incorporate Competition, 63 Operations Rsch. 1 (2015).
[159] Zach Brown & Alexander MacKay, Competition in Pricing Algorithms 3 (Sept. 14, 2020) (unpublished manuscript), https://ssrn.com/abstract=3485024.
[160] Joseph E Harrington Jr., Third Party Pricing Algorithms and The Intensity Of Competition, (June 8, 2020) (unpublished manuscript). For concerns about firms adopting similar algorithms, see, for example, CMA Report, supra note 18, at 14 (“if more firms utilize the same pricing algorithm in the same market, it makes it more likely that the market will move to an outcome where prices are higher.”).